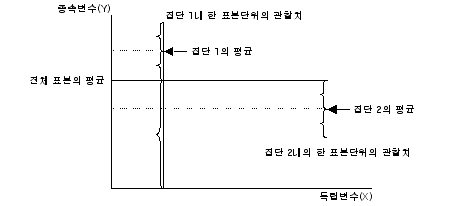
|
7. КаЛъКаМЎ(ANOVA)
КаЛъКаМЎРЬЖѕ ИэИёУДЕЕЗЮ УјСЄЕШ ЕЖИГКЏМіПЭ ЕюАЃ ЖЧДТ КёРВУДЕЕЗЮ УјСЄЕШ СОМгКЏМі ЛчРЬПЭ АќАшИІ
ПЌБИЧЯДТ ХыАшБтЙ§РдДЯДй. КаЛъКаМЎРК Еб РЬЛѓРЧ С§ДмЕщАЃПЁ ОюЖВ КЏМіРЧ ЦђБеСЁМіПЁ ТїРЬАЁ
РжДТСіИІ АЫСЄЧЯДТ АЭРдДЯДй. КаЛъКаМЎРК ЧЯГЊРЧ ЙќСжЧќ ЕЖИГКЏМіПЭ СОМгКЏМіАЃРЧ АќАшИІ КаМЎЧЯДТ
РЯПјКаЛъКаМЎАњ Еб РЬЛѓРЧ ЕЖИГКЏМіЕщРЛ ЧдВВ АэЗСЧпРЛ ЖЇ РЬЕщРЬ СОМгКЏМіПЁ ЙЬФЁДТ ШПАњИІ
КаМЎЧЯДТ РЬПјКаЛъКаМЎРИЗЮ КаЗљЧв Мі РжНРДЯДй. ИеРњ РЯПјКаЛъКаМЎРЛ ЛьЦьКИАкНРДЯДй.
ЁЁ
7.1 РЯПјКаЛъКаМЎ
ИэИёУДЕЕЗЮ БИМКЕШ ЕЖИГКЏМіПЭ ЕюАЃУДЕЕ РЬЛѓРИЗЮ БИМКЕШ СОМгКЏМіРЧ МіАЁ АЂАЂ ЧЯГЊОП РжДТ АцПьПЁ
ЛчПыЧЯДТ КаМЎРдДЯДй. РЯПјКаЛъКаМЎПЁДТ ЕЮ АГРЧ ЕЖИГЧЅКЛРЧ ЦђБеКёБГИІ ШЎРхЧб
РЯПјКаЛъКаМЎ(One-Way ANOVA)Ањ Paired-diffefence testИІ ШЎРхЧб
ЙЋРлРЇ КэЗЯЕ№РкРЮРЧ РЯПјКаЛъКаМЎРИЗЮ ГЊД Мі РжНРДЯДй. ЙЋРлРЇ КэЗЯЕ№РкРЮПЁ РЧЧб РЯПјКаЛъКаМЎРК
7.2ПЁМ ДйЗчЕЕЗЯ ЧЯАкНРДЯДй.
ЁЁ
ПЙ
МгПЪ ШИЛчПЁМ НХУМПЁ ЕћИЅ БтДЩМК МгПЪРЛ АГЙпЧЯБт РЇЧи НХУМРћ СЖАЧПЁ ЕћИЅ НХУМИИСЗЕЕИІ
СЖЛчЧЯБтЗЮ ЧЯПДДй. НХУМРћ СЖАЧПЁ ЕћЖѓ НХУМИИСЗЕЕПЁ ТїРЬАЁ РжДТСі ОЫОЦКИАэРк ЧбДй.
ЁЁ
1) АЁМГМГСЄ
КаЛъКаМЎПЁМ ПЕАЁМГРК АЂ С§ДмКА СОМгКЏМіРЧ ЦђБеАЊРЬ ЕПРЯЧЯДйДТ СЁРдДЯДй. ПЉБтМДТ С§ДмРЬ ПЉЗЏ
АГРЬЙЧЗЮ ДйРНАњ ААРЬ АЁМГРЬ МГСЄЕЫДЯДй.
ЁЁ
<ПЌБИАЁМГ> : НХУМРћ СЖАЧПЁ ЕћЖѓ НХУМИИСЗЕЕПЁ ТїРЬАЁ РжДй.
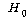 (ПЕАЁМГ)
: (ПЕАЁМГ)
: 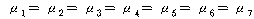
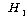 (ДыИГАЁМГ)
: РћОюЕЕ ОюДР ЕЮ С§ДмРК ДйИЃДй. (ДыИГАЁМГ)
: РћОюЕЕ ОюДР ЕЮ С§ДмРК ДйИЃДй.
ЁЁ
2) РЏРЧМіСи МГСЄ
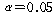
3) АЁСЄАЫХф
ЁЁ
КаЛъКаМЎРЛ РћПыЧЯБт РќПЁ СЖЛчРкДТ АЂ С§ДмРЧ ЦЏМКАњ АќЗУЧЯПЉ ДйРНАњ ААРК РќСІСЖАЧЕщРЬ
УцСЗЕЧДТСіИІ АЫХфЧиОп ЧеДЯДй.
Јч ЕЖИГМК : АЂ С§ДмРК МЗЮ ЕЖИГРћРЬОюОп ЧеДЯДй.
Јш СЄБдМК : АЂ С§ДмРЛ СЄБдКаЦїИІ РЬЗчОюОп ЧеДЯДй.
Јщ КвЦэМК : АЂ С§ДмКА КаЛъРЧ СЄЕЕАЁ КёНСЧиОп ЧеДЯДй.
ЁЁ
4) АЫСЄХыАшЗЎ
ЁЁ
КаЛъКаМЎПЁМДТ ЕЮ АГ РЬЛѓРЧ С§ДмЕщРЧ ЦђБеАЊРЛ КёБГЧЯБт РЇЧи FАЊРЛ АЫСЄХыАшЗЎРИЗЮ ЛчПыЧеДЯДй.
СЖЛчРкДТ С§ДмАЃРЧ ТїРЬИІ БИЧЯБт РЇЧи РќУМЦђБеАњ С§ДмЦђБеАЃРЧ ТїРЬПЭ С§ДмЦђБеАњ АГКААќТћФЁПЭРЧ
ТїРЬЗЮ БИКаЧЯПЉ АшЛъЧеДЯДй. Ся, (РќУМЦђБе-АГКААќТћАЊ) = (РќУМЦђБе-С§ДмЦђБе)+(С§ДмЦђБе-АГКААќТћАЊ)РИЗЮ
АшЛъЧеДЯДй.
ЁЁ
РЇ НФРЧ АЂ БИМКПфМвИІ СІАіЧЯИщ ММ АЁСі РЏЧќРЧ КаЛъРИЗЮ БИМКЕЫДЯДй.
ЁЁ
|
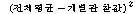 |
+ |
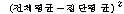 |
= |
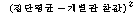 |
|
УбКЏЗЎ(SST) |
+ |
С§ДмАЃ КЏЗЎ(SSB) |
= |
С§ДмГЛ КЏЗЎ(SSW) |
АЂ БИМКПфМвРЧ АшЛъНФПЁ ДыЧи ЛьЦьКОНУДй.
ЁЁ
Јч УбКЏЗЎ(SST : sum of squares total)РК АЂ АќТћАЊЕщРЬ РќУМ ЧЅКЛРЧ
ЦђБеЕщРЛ СпНЩРИЗЮ ОѓИЖИИХ ЖГОюСЎ РжДТАЁИІ УјСЄЧЯДТ АЭРдДЯДй.
ЁЁ
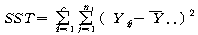
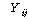 :
СОМгКЏМі :
СОМгКЏМі 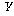 РЧ
АГКААќТћАЊ РЧ
АГКААќТћАЊ
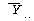 :
РќУМЧЅКЛПЁМРЧ СОМгКЏМіРЧ ЦђБе :
РќУМЧЅКЛПЁМРЧ СОМгКЏМіРЧ ЦђБе
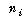 : С§Дм : С§Дм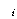 РЧ
ЧЅКЛ Мі РЧ
ЧЅКЛ Мі
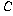 :
С§ДмРЧ Мі :
С§ДмРЧ Мі
ЁЁ
Јш С§ДмАЃ КЏЗЎ(SSB : sum of squares between groups)РК ЕЖИГКЏМіПЁ
РЧЧи ГЊДЉОюСј АЂ С§ДмРЧ ЦђБеРЬ РќУМЧЅКЛ ЦђБеРЧ СпНЩРИЗЮ ОѓИЖГЊ ЖГОюСЎ РжДТАЁИІ УјСЄЧЯДТ
АЭРдДЯДй.
ЁЁ
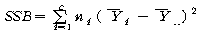
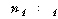 ЙјТА
С§ДмРЧ ЧЅКЛ Мі ЙјТА
С§ДмРЧ ЧЅКЛ Мі
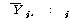 ЙјТА
С§ДмРЧ ЦђБе ЙјТА
С§ДмРЧ ЦђБе
ЁЁ
Јщ С§ДмГЛ КЏЗЎ(SSW : sum of squares within groups)РК АЂ
ЧЅКЛС§ДмГЛ АГКААќТћФЁЕщРЬ АЂ ЧЅКЛС§ДмРЧ ЦђБеРЛ СпНЩРИЗЮ ОюДР СЄЕЕ ЖГОюСЎ РжДТАЁИІ УјСЄЧЯДТ
АЭРдДЯДй.
ЁЁ
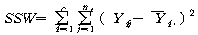
ЁЁ
С§ДмАЃ КЏЗЎАњ С§ДмГЛ КЏЗЎРЬ БИЧиСіИщ РЬИІ ХыЧи С§ДмАЃРЧ ТїРЬИІ АЫСЄЧв Мі РжНРДЯДй.
КаЛъКаМЎПЁМДТ С§ДмАЃ ТїРЬАЁ РЏРЧЧЯБт РЇЧиМДТ С§ДмГЛ КЏЗЎРК АЁДЩЧб РћОюОп ЧЯИч С§ДмАЃ КЏЗЎРК
АЁДЩЧб ФПОп ЧеДЯДй. РЬИІ РЇЧи КаЛъКаМЎПЁМДТ С§ДмАЃ КаЛъФЁПЭ С§ДмГЛ КаЛъФЁРЧ ЛѓДыРћРЮ КёРВРЛ
ГЊХИГЛДТ 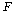 ХыАшЗЎРЛ
РЬПыЧЯПЉ С§ДмАЃ ТїРЬПЁ ДыЧб АЫСЄРЛ ЧеДЯДй. ХыАшЗЎРЛ
РЬПыЧЯПЉ С§ДмАЃ ТїРЬПЁ ДыЧб АЫСЄРЛ ЧеДЯДй.
ЁЁ
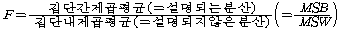
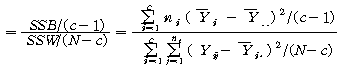
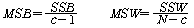
ЁЁ
КаЛъКаМЎПЁМРЧ РкРЏЕЕДТ ХЉАд ММ АЁСіРдДЯДй.
С§ДмАЃ КЏЗЎРЧ РкРЏЕЕДТ ЕЖИГЧЅКЛРЧ Мі - 1(=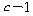 )РЬАэ,
С§ДмГЛ КЏЗЎРЧ РкРЏЕЕДТ ЛчЗЪМі - ЕЖИГЧЅКЛ Мі(= )РЬАэ,
С§ДмГЛ КЏЗЎРЧ РкРЏЕЕДТ ЛчЗЪМі - ЕЖИГЧЅКЛ Мі(=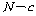 ),
УбКЏЗЎРЧ РкРЏЕЕДТ ЛчЗЪМі - 1(= ),
УбКЏЗЎРЧ РкРЏЕЕДТ ЛчЗЪМі - 1(=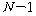 )РдДЯДй. )РдДЯДй.
ЁЁ
РЬИІ ХфДыЗЮ КаЛъКаМЎЧЅИІ РлМКЧи КЛ ШФ КаМЎЧи КОНУДй.
ЁЁ
|
Source |
СІАіЧе SS |
РкРЏЕЕ df |
СІАіЦђБе MS |
F |
|
С§ДмАЃ КЏЗЎ |
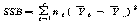 |
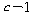 |
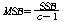 |
 |
|
|
|
|
|
|
|
С§ДмГЛ КЏЗЎ |
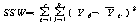 |
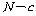 |
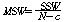 |
ЁЁ |
|
УбКЏЗЎ |
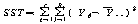 |
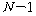 |
ЁЁ |
ЁЁ |
СЖЛчРкДТ С§ДмАЃ ТїРЬПЁ ДыЧб АЁМГМГСЄРЛ РЇЧи
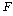 РЧ РгАшФЁИІ
БИЧиОп ЧеДЯДй. РЧ РгАшФЁИІ
БИЧиОп ЧеДЯДй.
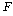 РЧ РгАшФЁДТ
РЏРЧМіСиАњ АЂАЂРЧ РкРЏЕЕПЁ ЕћЖѓ АсСЄРЬ ЕЫДЯДй. ИИОр АшЛъЕШ РЧ РгАшФЁДТ
РЏРЧМіСиАњ АЂАЂРЧ РкРЏЕЕПЁ ЕћЖѓ АсСЄРЬ ЕЫДЯДй. ИИОр АшЛъЕШ
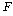 АЊРЬ АЊРЬ
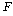 РЧ РгАшФЁ
(= РЧ РгАшФЁ
(=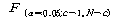 )АЊКИДй
РлРИИщ, ПЕАЁМГРЛ УЄХУЧЯАд ЕЫДЯДй. ЙнДыЗЮ )АЊКИДй
РлРИИщ, ПЕАЁМГРЛ УЄХУЧЯАд ЕЫДЯДй. ЙнДыЗЮ
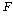 АЊРЬ АЊРЬ
 РЧ РгАшФЁ
(= РЧ РгАшФЁ
(= )АЊКИДй
ХЉИщ, ПЕАЁМГРЛ БтАЂЧЯАэ С§ДмАЃ ТїРЬАЁ РжДйАэ АсЗаСіРЛ Мі РжНРДЯДй. )АЊКИДй
ХЉИщ, ПЕАЁМГРЛ БтАЂЧЯАэ С§ДмАЃ ТїРЬАЁ РжДйАэ АсЗаСіРЛ Мі РжНРДЯДй.
ЁЁ
5) НЧЧрЙцЙ§
ЁЁ
РЯПјКаЛъКаМЎРЛ НУРлЧЯБт РЇЧи
[ПЙСІ 09-1]ЦФРЯРЛ
ПОюКОДЯДй. ЦФРЯРЛ ПИщ ЕЅРЬХЭ ЦэС§БтПЁ 6АГРЧ КЏМіАЁ РжНРДЯДй. 2РхПЁМ КЏМіКЏШЏПЁ ДыЧи
ЙшПю РћРЬ РжСіПф? ПЉБтМДТ 5АГРЧ КЏМіИІ НХУМИИСЗЕЕЖѓДТ ЧЯГЊРЧ КЏМіЗЮ ЧеФЁЗСАэ ЧеДЯДй.
2РхРЛ ЙшПю ГЛПыРЛ ХфДыЗЮ АЃДмШї МГИэРЛ ЧЯАкНРДЯДй.
ЁЁ
ПьМБ КЏМіКЏШЏРЛ РЇЧи КЏШЏИоДКПЁ ЕщОюАЁМ КЏМіАшЛъРЛ ХЌИЏЧи СнДЯДй. ХА, ИіЙЋАд, АЁНПЕбЗЙ,
ЧуИЎЕбЗЙ, ШќЕбЗЙРЧ КЏМіДТ И№ЕЮ АЂАЂПЁ ДыЧб РкНХРЧ ИИСЗЕЕИІ УјСЄЧб АЭРдДЯДй. РЬПЁ ДыЧб
ИИСЗЕЕИІ ЧЯГЊРЧ НХУМИИСЗЕЕЗЮ ИИЕщОюСжБт РЇЧи ДйМИ АГРЧ КЏМіИІ ЧеЧб ШФ Бз АЊРЛ КЏМіРЧ АГМіЗЮ
ГЊДЉОюСнДЯДй.
ЁЁ
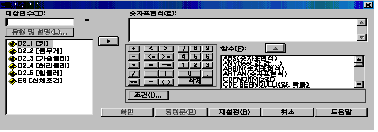
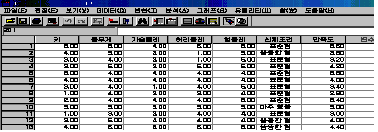
РЬ Р§ТїИІ ЕћЖѓ ЧЯИщ [БзИВ 7.1]Ањ ААРК ДыШЛѓРкАЁ ГЊХИГГДЯДй.
ЁЁ
ДыЛѓКЏМіПЁДТ ЛѕЗЮ Л§МКЧв КЏМіИэРЛ РћОю ГжНРДЯДй. ПЉБтМДТ НХУМИИСЗЕЕПЁ АќЧб ГЛПыРЛ РћРИИщ
ЕЧСіИИ БлРкМіДТ ЧбБлРЮ АцПь 4Рк, ПЕЙЎРЮ АцПь 8РкЗЮ СІЧбЕЧОю РжРИЙЧЗЮ ЁЎИИСЗЕЕЁЏЖѓАэ
РдЗТЧеДЯДй. БзЗЏИщ РЏЧќ Йз МГИэ(L) ЙіЦАРЬ ГЊХИГЊДТЕЅ БзАЭРЛ ХЌИЏЧЯПЉ МГИэПЁДТ
[НХУМИИСЗЕЕ]ИІ РдЗТЧЯАэ РЏЧќПЁДТ М§РкЗЮ РдЗТЧЯПДРИЙЧЗЮ [М§Рк]ЗЮ МГСЄЧи СнДЯДй.
КЏМіИёЗЯ ФПЁ РжДТ КЏМі Сп АшЛъЧЯБт РЇЧб КЏМіИІ АЁПюЕЅ КЮКаПЁ РжДТ МіНФРЛ АЁСіАэ М§РкЧЅЧіНФ(E)
ОШПЁ АшЛъНФРЛ РћОю ГжНРДЯДй. [(ХА + ИіЙЋАд + АЁНПЕбЗЙ + ЧуИЎЕбЗЙ + ШќЕбЗЙ) / 5]ИІ
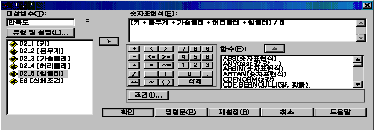
РдЗТЧеДЯДй. [БзИВ 7.2]УГЗГ РдЗТЧЯНУИщ ЕЫДЯДй.
ЁЁ
ЁЁ
БзЗБ ШФПЁ [ШЎРЮ]РЛ ДЉИЃИщ [БзИВ 7.3]Ањ ААРЬ ЕЅРЬХЭ ЦэС§Бт УЂПЁ ЁЎИИСЗЕЕЁЏЖѓДТ КЏМіАЁ
Л§МКЕЫДЯДй.
ЁЁ
БзЗЏИщ РЬСІКЮХЭ НХУМСЖАЧАњ ИИСЗЕЕЖѓДТ КЏМіИІ АЁСіАэ РЯПјКаЛъКаМЎРЛ НЧНУЧЯАкНРДЯДй. Р§ТїДТ
ДйРНАњ ААНРДЯДй.
ЁЁ
|
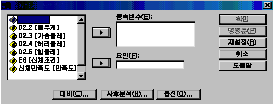
КаМЎ(A)ЁцЦђБеКёБГ(M)ЁцРЯПјЙшФЁ КаЛъКаМЎ(O) |
ЁЁ
РЬ Р§ТїИІ ЕћИЃИщ [БзИВ 7.4]РЧ ДыШЛѓРкАЁ ГЊХИГГДЯДй.
ЁЁ
ЁЁ
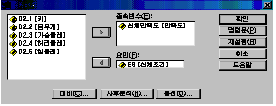
ПоТЪ КЏМі ИёЗЯ ФПЁ РжДТ КЏМі СпПЁ СОМгКЏМіРЮ НХУМИИСЗЕЕИІ СОМгКЏМі(E)ФПЁ ЕЖИГКЏМіРЮ
НХУМСЖАЧРЛ ПфРЮ(F)ФПЁ ПХАмГѕНРДЯДй.
ЁЁ
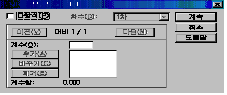
Јч ДыКё(C)
ЁЁ
ДыКёЖѕ ОюЖВ КЏМіПЁ РЧЧи ФЩРЬНКЕщРЬ ПЉЗЏ АГРЧ С§ДмРИЗЮ ГЊДЉОюСј АцПь, Бз СпПЁМ МЗЮ
АјХыРћРЮ ЦЏМКРЬ РжДТ С§ДмГЂИЎ ЙОюМ ЕЮ АЁСіЗЮ ЙќСжШЧб ШФ ЕЮ ЙќСжРЧ ЦђБе ТїРЬПЁ ДыЧб
T-testИІ ЧЯДТ БтДЩРдДЯДй. ИИРЯ КЏМі1Ањ КЏМі3РЬ АјХыРћРЬАэ КЏМі2ПЭ КЏМі4АЁ
АјХыРћРЬЖѓИщ РЬПЁ ДыЧб ДыКё НФРК ДйРНАњ ААНРДЯДй.
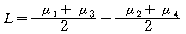
ЁЁ
ДыКёПЁ АќЧб АЭРЛ МГСЄЧи СжБт РЇЧиМДТ АшМі(O)ФПЁ АЂ С§ДмПЁ ЧвДчЕШ УГРНКЮХЭ МјМДыЗЮ
РдЗТЧб ШФ [УпАЁ]ИІ ДЉИЈДЯДй. ПЉБтМ СжРЧЧв АЭРК Бз РдЗТЕШ АЊЕщРЧ ЧеРЬ 1РЬ ЕЧОюОп ЧбДйДТ
АЭРдДЯДй.
ИИРЯ ДйИЅ setПЁМЕЕ ЙќСжАЃ ДыКёИІ ЧЯАэРк ЧЯИщ [ДйРН(N)] ЙіЦАРЛ ДЗЏМ ААРК ЙцНФРИЗЮ
МГСЄЧи СжИщ ЕЫДЯДй.
ЁЁ
Јш ЛчШФКаМЎ(H)
ЁЁ
ЛчШФКаМЎПЁМДТ Tukey, Duncan, Scheffe ЕюРЬ ИЙРЬ ОВРдДЯДй.
TukeyЙ§РК АЂ МПРЧ ХЉБтАЁ ААРК АцПьПЁИИ ЛчПыЧеДЯДй. TukeyЙ§РК АЁРх КИМіРћРЮ
ЙцЙ§РдДЯДй. КИМіРћРЬЖѕ ИЛРК НБАд ЦђБеПЁ ТїРЬАЁ РЏРЧЙЬЧЯДйАэ АсЗа СўСі ОЪДТДйДТ ИЛРдДЯДй.
ScheffeЙ§Ањ BonferroniЙ§РК АЂ МПРЧ ХЉБтАЁ АААХГЊ ДйИЃАХГЊ ЛѓАќОјРЬ ЛчПыЧв Мі
РжНРДЯДй. ScheffeЙ§РЧ АцПь ПЉЗЏАГРЧ ДыКёЕщРЛ ЕПНУПЁ АЫСЄЧЯДТ АЭПЁ РЏШПЧЯАд ЛчПыЧв Мі
РжНРДЯДй.
Јщ ПЩМЧ(O)
ЁЁ
|
ХыАшЗЎ |
БтМњХыАш(D) |
ФЩРЬНК Мі, ЦђБе, ЧЅСиЦэТї ЕюРЧ БтМњХыАшЗЎРЬ УтЗТЕЫДЯДй. |
|
КаЛъРЧ ЕПСњМК(H) |
КаЛъКаМЎРЛ ЧЯБт РЇЧи КаЛъРЬ ЕПРЯЧЯДйДТ АЁСЄРЛ РгРЧЗЮ ЧЯАд ЕЫДЯДй. БзЗЏГЊ ЧЅКЛРЬ
ЙЋРлРЇЗЮ УпУтЕЧОњБт ЖЇЙЎПЁ Бз АЁСЄРЬ УцСЗЕЧДТСі ОЫОЦКИОЦОп ЧЯЙЧЗЮ LeveneРЧ
ХыАшЗЎРЛ РЬПыЧеДЯДй. |
|
ЕЕЧЅ |
ЦђБеЕЕЧЅ(M) |
РЬ КаМЎПЁ ДыЧб ЕЕЧЅАЁ УтЗТЕЫДЯДй. |
|
АсУјАЊ |
КаМЎКА АсУјАЊ СІПм(A) |
ЧиДч АЫСѕАњ АќЗУЕШ КЏМіПЁ ДыЧи АсУјАЊРЬ РжДТ ФЩРЬНКИІ КаМЎПЁМ СІПмНУХЕДЯДй. |
|
ИёЗЯКА АсУјАЊ СІПм(L) |
АсУјАЊРЬ РжДТ ФЩРЬНКДТ И№Еч КаМЎПЁМ СІПмНУХЕДЯДй. |
ЁЁ
-->БтМњХыАш
НХУМИИСЗЕЕ
ЁЁ
|
ЁЁ |
N |
ЦђБе |
ЧЅСи
ЦэТї |
ЧЅСи
ПРТї |
ЦђБеПЁ ДыЧб 95% НХЗкБИАЃ |
УжМвАЊ |
УжДыАЊ |
|
ЧЯЧбАЊ |
ЛѓЧбАЊ |
|
ОЦСж ИЖИЅ Чќ |
1 |
4.2000 |
. |
. |
. |
. |
4.20 |
4.20 |
|
ИЖИЅ Чќ |
29 |
3.3310 |
.6240 |
.1159 |
3.0937 |
3.5684 |
2.40 |
4.80 |
|
ГЏОРЧб Чќ |
18 |
3.1333 |
.9653 |
.2275 |
2.6533 |
3.6134 |
1.00 |
5.00 |
|
ЧЅСиЧќ |
157 |
3.3962 |
.6742 |
.0053 |
3.2899 |
3.5025 |
1.00 |
5.00 |
|
ЖзЖзЧб Чќ |
89 |
3.8966 |
.6530 |
.0069 |
3.7591 |
4.0342 |
2.40 |
5.00 |
|
ОЦСж ЖзЖзЧб Чќ |
11 |
4.4364 |
.4632 |
.1397 |
4.1252 |
4.7475 |
3.60 |
5.00 |
|
ХыХыЧб Чќ |
36 |
3.6278 |
.6345 |
.1058 |
3.4131 |
3.8425 |
2.20 |
5.00 |
|
ЧеАш |
341 |
3.5677 |
.7266 |
.0039 |
3.4903 |
3.6451 |
1.00 |
5.0 |
ЁЁ
РЇРЧ ЧЅПЁМДТ АЂ НХУМСЖАЧПЁ ЕћИЅ С§ДмКА ФЩРЬНК Мі, ЦђБе, ЧЅСиЦэТї, ЧЅСиПРТї, АЂ С§Дм
ЦђБеПЁ ДыЧб 95% НХЗкБИАЃ, АЂ С§ДмКА УжМвАЊАњ УжДыАЊРЬ ГЊХИГЊРжНРДЯДй.
-->КаЛъРЧ
ЕПСњМКПЁ ДыЧб АЫСЄ
НХУМИИСЗЕЕ
ЁЁ
|
Levene ХыАшЗЎ |
РкРЏЕЕ1 |
РкРЏЕЕ2 |
РЏРЧШЎЗќ |
|
.686 |
6 |
334 |
.661 |
ЁЁ
РЇРЧ ЧЅПЁМДТ АЂ И№С§ДмРЧ КаЛъРЬ ААДйДТ АЁСЄПЁ ДыЧб АЫСѕРЛ Чб АЊРдДЯДй. LeveneРЧ
ХыАшЗЎПЁМ РЏРЧШЎЗќРК .661РЬЙЧЗЮ
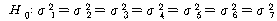 РЛ
БтАЂЧЯСі ИјЧЯЙЧЗЮ ЕюКаЛъМК АЁСЄПЁ ЙЎСІАЁ ОјДйАэ Чв Мі РжНРДЯДй. РЛ
БтАЂЧЯСі ИјЧЯЙЧЗЮ ЕюКаЛъМК АЁСЄПЁ ЙЎСІАЁ ОјДйАэ Чв Мі РжНРДЯДй.
ЁЁ
-->КаЛъКаМЎ
НХУМИИСЗЕЕ
ЁЁ
|
ЁЁ |
СІАіЧе |
РкРЏЕЕ |
ЦђБеСІАі |
F |
РЏРЧШЎЗќ |
|
С§Дм-АЃ |
28.099 |
6 |
4.683 |
10.330 |
.000 |
|
С§Дм-ГЛ |
151.426 |
334 |
.453 |
ЁЁ |
ЁЁ |
|
ЧеАш |
179.525 |
340 |
ЁЁ |
ЁЁ |
ЁЁ |
РЇРЧ КаЛъКаМЎ ЧЅПЁМДТ
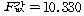 РЬАэ,
РЏРЧШЎЗќ РЬАэ,
РЏРЧШЎЗќ 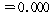 РЬЙЧЗЮ РЬЙЧЗЮ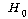 (ПЕАЁМГ)
: (ПЕАЁМГ)
: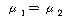 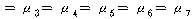 ИІ
БтАЂЧеДЯДй. ЕћЖѓМ АЂ НХУМСЖАЧПЁ ЕћЖѓ НХУМПЁ ДыЧб ИИСЗЕЕПЁДТ ТїРЬАЁ РжДйАэ Чв Мі РжНРДЯДй. ИІ
БтАЂЧеДЯДй. ЕћЖѓМ АЂ НХУМСЖАЧПЁ ЕћЖѓ НХУМПЁ ДыЧб ИИСЗЕЕПЁДТ ТїРЬАЁ РжДйАэ Чв Мі РжНРДЯДй.
ЁЁ
7.2 РЯПјКаЛъКаМЎ - ЙЋРлРЇ КэЗАЕ№РкРЮ
ЁЁ
ЙЋРлРЇ КэЗЯЕ№РкРЮПЁ ДыЧб КаЛъКаМЎРК paired - difference testИІ ШЎРхЧб
АЭРИЗЮ ОеРЧ КаМЎАњДТ ДоИЎ ПмЛ§КЏМіЗЮ РлПыЧв Мі РжДТ КЏМіИІ ХыСІЧЯБт РЇЧи КэЗЯМГСЄЧЯПЉ
УГИЎЧЯДТ ЙцЙ§РдДЯДй.
ЁЁ
ПЙ
ЁЁ
ШоДыЦљРЧ ЛіЛѓПЁ ДыЧи СЖЛчЧЯБт РЇЧи ДыИЎСЁ 4БКЕЅИІ МБСЄЧЯПЉ ШоДыЦљРЧ ЛіЛѓИИРЛ КёБГЧЯБт РЇЧи
ДйИЅ ПмЛ§КЏМі(ДыИЎСЁРЧ ХЉБт, АэАД Мі, Бз СіПЊРЧ АцСІРћ ПЉАЧ Ею)ИІ СІАХЧб ДйРН ШоДыЦљРЧ
БИИХКѓЕЕИІ СЖЛчЧЯЗСАэ ЧбДй. ШоДыЦљРЧ ЛіЛѓПЁ ЕћЖѓ БИИХКѓЕЕПЁДТ ТїРЬАЁ РжДТСі ОЫОЦКИРк.
ЁЁ
1) АЁМГМГСЄ
ЁЁ
<ПЌБИАЁМГ> : ШоДыЦљ ЛіЛѓПЁ ЕћЖѓ БИИХКѓЕЕПЁДТ ТїРЬАЁ РжДй.
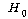 (ПЕАЁМГ)
: (ПЕАЁМГ)
: 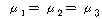
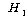 (ДыИГАЁМГ)
: РћОюЕЕ ОюДР ЕЮ С§ДмРК ДйИЃДй. (ДыИГАЁМГ)
: РћОюЕЕ ОюДР ЕЮ С§ДмРК ДйИЃДй.
ЁЁ
2) РЏРЧМіСи МГСЄ
ЁЁ
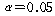
ПЉБтМДТ АЁСЄАњ АЫСЄХыАшЗЎРЬ РЇРЧ РЯПјКаЛъКаМЎАњ ЕПРЯЧЯЙЧЗЮ Л§ЗЋЧЯАэ НЧЧрЙцЙ§РИЗЮ
ГбОюАЁАкНРДЯДй.
ЁЁ
3) НЧЧрЙцЙ§
ЁЁ
ЙЋРлРЇ КэЗЯЕ№РкРЮПЁ РЧЧб РЯПјКаЛъКаМЎРЛ НУРлЧЯБт РЇЧи
[ПЙСІ 9-2]ИІ
КвЗЏ ДйРНАњ ААРК Р§ТїИІ ЕћЖѓЧеДЯДй.
ЁЁ
|
КаМЎ(A)ЁцРЯЙнМБЧќИ№Чќ(G)ЁцРЯКЏЗЎ(U) |
РЬ Р§ТїИІ ЕћИЃИщ [БзИВ 7.9]ПЭ ААРК ДыШЛѓРкАЁ ГЊХИГГДЯДй.
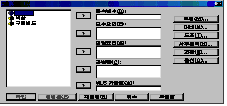
ПоТЪ КЏМіИёЗЯ ФПЁ РжДТ КЏМі Сп СОМгКЏМіИІ СОМгКЏМі(D) ФРИЗЮ, ЕЖИГКЏМіИІ И№МіПфРЮ(F)
ФРИЗЮ ПХБщДЯДй. БзЗБ ДйРН ГЊИгСі ПЩМЧРЛ МГСЄЧЯБт РЇЧи РкММШї ОЫОЦКОНУДй.
ЁЁ
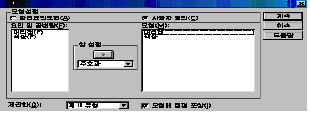
Јч И№Чќ(M)
ЁЁ
|
ПЯРќПфРЮИ№Чќ(A) |
ПЯРќПфРЮИ№ЧќПЁМДТ СжШПАњ, КэЗЯКЏМіШПАњ, ЛѓШЃРлПыШПАњ, Р§Цэ Ею И№Еч АЭРЬ И№ЧдЕШ
ЛѓХТПЁМ КаМЎРЛ Чи СнДЯДй. |
|
ЛчПыРкСЄРЧ(C) |
ПЯРќПфРЮИ№ЧќПЁ РжДТ БтДЩ Сп РЯКЮИИРЛ МБХУЧЯПЉ КаМЎЧи СжДТ АЭРдДЯДй.
|
|
СІАіЧе(Q) |
СІЅВРЏЧќ |
СІАіЧб АшЛъЙ§РЛ МГСЄЧЯДТ АЭРИЗЮМ АсУјМПРЬ ОјДТ И№ЧќРЧ АцПьПЁ РЯЙнРћРИЗЮ ЛчПыЕЫДЯДй. |
|
СІЅГРЏЧќ |
СІАіЧб АшЛъЙ§РЛ МГСЄЧЯДТ АЭРИЗЮМ АсУјМПРЬ РжДТ И№ЧќРЧ АцПьПЁ РЯЙнРћРИЗЮ ЛчПыЕЫДЯДй. |
ПЉБтМДТ ДыИЎСЁРЛ КэЗЯКЏМіЗЮ МГСЄЧЯАэ ЛіЛѓПЁ ДыЧб СжШПАњИІ ХыЧи БИИХКѓЕЕИІ ОЫОЦКИАэРк ЧЯДТ
АЭРЬЙЧЗЮ ЛчПыРкСЄРЧ(C)ИІ МБХУЧЯПЉ ЕЮ КЏМіИІ И№Чќ(M)РИЗЮ ПХБф ШФ [СжШПАњ]ЗЮ МГСЄЧи
СнДЯДй. [БзИВ 7.10]Ањ ААРЬ МГСЄЕЧЕЕЗЯ ЧЯИщ ЕЫДЯДй.
Бз ЙлПЁ [ДыКё(N), ЕЕЧЅ(T), РњРх(S)] ЕюРК СЖАЧРК БтКЛМГСЄ БзДыЗЮ ЕгДЯДй.
ЁЁ
Јш ЛчШФКаМЎ(H)
ЁЁ
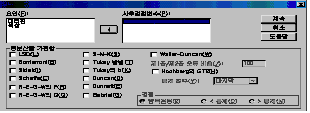
ПЉБтМДТ ЛіЛѓПЁ ЕћИЅ БИИХКѓЕЕПЁ ДыЧб ТїРЬИІ ОЫАэРк ЧЯДТ АЭРЬЙЧЗЮ ПфРЮ(F)ПЁ РжДТ КЏМі Сп
ЛіЛѓРЛ ЛчШФАЫСЄКЏМі(P)ЗЮ ПХБф ШФ МПРЧ ХЉБтАЁ ЕПРЯЧЯЙЧЗЮ Tukey ЙцЙ§(T)ПЁ ХЌИЏРЛ Чб
ДйРН [АшМг]РЛ ДЉИЈДЯДй.
Јщ ПЩМЧ(O)
ЁЁ
ПЉБтМДТ ДмМјШї БтМњХыАшЗЎИИРЛ МГСЄЧи Си ШФ [АшМг]РЛ ДЉИЅ ДйРН [ШЎРЮ]РЛ ДЉИЃИщ ДйРНАњ
ААРК АсАњУЂРЬ ГЊХИГГДЯДй.
-->АГУМ-АЃ
ПфРЮ
ЁЁ
|
ЁЁ |
КЏМіАЊ МГИэ |
N |
|
ДыИЎСЁ |
1 |
ЁЁ |
3 |
|
2 |
ЁЁ |
3 |
|
3 |
ЁЁ |
3 |
|
4 |
ЁЁ |
3 |
|
ЛіЛѓ |
1 |
ШђЛі |
4 |
|
2 |
РКЛі |
4 |
|
3 |
АЫСЄЛі |
4 |
АГУМАЃ ПфРЮ ЧЅПЁМДТ АЂ ФЩРЬНККА МіАЁ ГЊХИГЊ РжНРДЯДй.
ЁЁ
-->БтМњХыАшЗЎ
СОМгКЏМі: БИИХКѓЕЕ
ЁЁ
|
ДыИЎСЁ |
ЛіЛѓ |
ЦђБе |
ЧЅСиЦэТї |
N |
|
1 |
ШђЛі |
17.00 |
. |
1 |
|
РКЛі |
34.00 |
. |
1 |
|
АЫСЄЛі |
23.00 |
. |
1 |
|
ЧеАш |
24.67 |
8.62 |
3 |
|
2 |
ШђЛі |
15.00 |
. |
1 |
|
РКЛі |
26.00 |
. |
1 |
|
АЫСЄЛі |
21.00 |
. |
1 |
|
ЧеАш |
20.67 |
5.51 |
3 |
|
3 |
ШђЛі |
1.00 |
. |
1 |
|
РКЛі |
23.00 |
. |
1 |
|
АЫСЄЛі |
8.00 |
. |
1 |
|
ЧеАш |
10.67 |
11.24 |
3 |
|
4 |
ШђЛі |
6.00 |
. |
1 |
|
РКЛі |
22.00 |
. |
1 |
|
АЫСЄЛі |
16.00 |
. |
1 |
|
ЧеАш |
14.67 |
8.08 |
3 |
|
ЧеАш |
ШђЛі |
9.75 |
7.54 |
4 |
|
РКЛі |
26.25 |
5.44 |
4 |
|
АЫСЄЛі |
17.00 |
6.68 |
4 |
|
ЧеАш |
17.67 |
9.25 |
12 |
БтМњХыАшЗЎ ЧЅПЁМДТ АЂ БИИХКѓЕЕПЭ ЦђБе, ЧЅСиЦэТїАЁ СІНУЕЧОю РжНРДЯДй.
АГУМ-АЃ ШПАњ АЫСЄ
СОМгКЏМі: БИИХКѓЕЕ
ЁЁ
|
МвНК |
СІ III РЏЧќ СІАіЧе |
РкРЏЕЕ |
ЦђБеСІАі |
F |
РЏРЧШЎЗќ |
|
МіСЄ И№Чќ |
895.167(a) |
5 |
179.033 |
23.609 |
.001 |
|
Р§Цэ |
3745.333 |
1 |
3745.333 |
493.890 |
.000 |
|
ДыИЎСЁ |
348.000 |
3 |
116.000 |
15.297 |
.003 |
|
ЛіЛѓ |
547.167 |
2 |
273.583 |
36.077 |
.000 |
|
ПРТї |
45.500 |
6 |
7.583 |
ЁЁ |
ЁЁ |
|
ЧеАш |
4686.000 |
12 |
ЁЁ |
ЁЁ |
ЁЁ |
|
МіСЄ ЧеАш |
940.667 |
11 |
ЁЁ |
ЁЁ |
ЁЁ |
|
a R СІАі = .952 (МіСЄЕШ R СІАі = .911) |
ЁЁ
АГУМАЃ ШПАњАЫСЄ ЧЅПЁМДТ ЛіЛѓПЁ ЕћЖѓ БИИХКѓЕЕПЁ ТїРЬАЁ РжДТСі, ДыИЎСЁПЁ ЕћЖѓ БИИХКѓЕЕПЁ
ТїРЬАЁ РжДТСіПЁ ДыЧб КаМЎАсАњАЁ ГЊХИГЊ РжНРДЯДй. КаМЎЧб АсАњ РЬАэ, РЏРЧШЎЗќРЬ
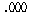 РЬЙЧЗЮ РЬЙЧЗЮ
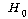 (ПЕАЁМГ)
: (ПЕАЁМГ)
: 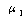 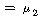 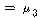 РК РК
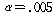 ПЁМ БтАЂЕЩ
Мі РжНРДЯДй. ЕћЖѓМ ЛіЛѓПЁ ЕћИЅ БИИХКѓЕЕПЁДТ ТїРЬАЁ РжДйАэ АсЗаСіРЛ Мі РжНРДЯДй. УпАЁРћРИЗЮ
ДыИЎСЁПЁ АќЧб КаМЎРЛ ЛьЦьКИИщ, ПЁМ БтАЂЕЩ
Мі РжНРДЯДй. ЕћЖѓМ ЛіЛѓПЁ ЕћИЅ БИИХКѓЕЕПЁДТ ТїРЬАЁ РжДйАэ АсЗаСіРЛ Мі РжНРДЯДй. УпАЁРћРИЗЮ
ДыИЎСЁПЁ АќЧб КаМЎРЛ ЛьЦьКИИщ,
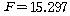 РЬАэ,
РЏРЧШЎЗќРЬ РЬАэ,
РЏРЧШЎЗќРЬ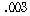 РЬЙЧЗЮ РЬЙЧЗЮ
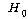 (ПЕАЁМГ)
: (ПЕАЁМГ)
: 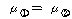 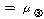  ДТ ДТ
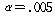 ПЁМ БтАЂЕЩ
Мі РжНРДЯДй. БзЗЏЙЧЗЮ АЂ ДыИЎСЁПЁ ЕћИЅ БИИХКѓЕЕПЁДТ ТїРЬАЁ РжДйАэ КМ Мі РжНРДЯДй. ПЁМ БтАЂЕЩ
Мі РжНРДЯДй. БзЗЏЙЧЗЮ АЂ ДыИЎСЁПЁ ЕћИЅ БИИХКѓЕЕПЁДТ ТїРЬАЁ РжДйАэ КМ Мі РжНРДЯДй.
ЁЁ
ЛчШФАЫСЄ- -->ДйСп КёБГ(ЛіЛѓ)
СОМгКЏМі: БИИХКѓЕЕ
Tukey HSD
ЁЁ
|
ЁЁ |
ЦђБеТї(I-J) |
ЧЅСиПРТї |
РЏРЧШЎЗќ |
95% НХЗкБИАЃ |
|
(I) ЛіЛѓ |
(J) ЛіЛѓ |
ЧЯЧбАЊ |
ЛѓЧбАЊ |
|
ШђЛі |
РКЛі |
-16.50(*) |
1.95 |
.000 |
-22.47 |
-10.53 |
|
АЫСЄЛі |
-7.25(*) |
1.95 |
.023 |
-13.22 |
-1.28 |
|
РКЛі |
ШђЛі |
16.50(*) |
1.95 |
.000 |
10.53 |
22.47 |
|
АЫСЄЛі |
9.25(*) |
1.95 |
.008 |
3.28 |
15.22 |
|
АЫСЄЛі |
ШђЛі |
7.25(*) |
1.95 |
.023 |
1.28 |
13.22 |
|
РКЛі |
-9.25(*) |
1.95 |
.008 |
-15.22 |
-3.28 |
|
АќУјЕШ ЦђБеПЁ БтУЪЧеДЯДй. |
|
* .05 МіСиПЁМ ЦђБеТїДТ РЏРЧЧеДЯДй. |
ЛчШФАЫСЄЧЅПЁМДТ ОюДР ЕЮ ЛіЛѓАЃПЁ БИИХКѓЕЕПЁМРЧ ТїРЬАЁ РжДТСіИІ ОЫЗССнДЯДй. АЂ ЦђБеТїАЊПЁ
ЕћИЅ РЏРЧШЎЗќРЬ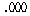 РИЗЮ
И№ЕЮ РЏРЧЙЬЧб АЊРЬ ГЊПдРИЙЧЗЮ РИЗЮ
И№ЕЮ РЏРЧЙЬЧб АЊРЬ ГЊПдРИЙЧЗЮ
 , ,
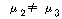 , ,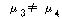 , ,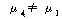 РЬИч,
ЕћЖѓМ ЛіЛѓ ШђЛі, РКЛі, АЫСЄЛіПЁ ЕћЖѓ БИИХКѓЕЕДТ МЗЮ ДйИЃДйАэ АсЗаСіРЛ Мі РжНРДЯДй. РЬИч,
ЕћЖѓМ ЛіЛѓ ШђЛі, РКЛі, АЫСЄЛіПЁ ЕћЖѓ БИИХКѓЕЕДТ МЗЮ ДйИЃДйАэ АсЗаСіРЛ Мі РжНРДЯДй.
ЁЁ
7.3 РЬПјКаЛъКаМЎ
ЁЁ
СіБнБюСіДТ ЧЯГЊРЧ ЕЖИГКЏМіПЭ СОМгКЏМіАЃРЧ АќАшИІ АЫСЄЧЯДТ ЕЅ РЬПыЕЧДТ РЯПјКаЛъКаМЎПЁ ДыЧиМ
МГИэЧЯПДНРДЯДй. БзЗЏГЊ НЧСІПЁМДТ ЧЯГЊРЧ ЕЖИГКЏМіКИДйДТ Еб РЬЛѓРЧ ЕЖИГКЏМіПЁ ЕћИЅ СОМгКЏМіПЭРЧ
АќАшПЁ ДыЧи Дѕ ИЙРК АќНЩРЛ АЁСіДТ АцПьАЁ ИЙНРДЯДй. РЬПЭ ААРЬ Еб РЬЛѓРЧ ЕЖИГКЏМіПЭ
СОМгКЏМіАЃРЧ АќАшПЁ АќЧи КаМЎЧЯДТ АЭРЛ РЬПјКаЛъКаМЎ(Two-Way ANOVA)ЖѓАэ ЧЯИч,
ЕЖИГКЏМіАЁ 3РЮ АцПьПЁДТ ЛяПјКаЛъКаМЎ(Three-way ANOVA)РЬЖѓАэ ЧеДЯДй.
РЬПјКаЛъКаМЎПЁМДТ ЕЖИГКЏМіАЁ СОМгКЏМіПЁ ЙЬФЁДТ СжШПАњПЭ ЛѓШЃРлПыШПАњИІ АЫСЄЧв Мі РжДТ РЬСЁРЬ
РжНРДЯДй. СжШПАњ(main effect)ЖѓДТ АЭРК Чб ЕЖИГКЏМіРЧ КЏШАЁ АсАњКЏМіПЁ ЙЬФЁДТ
ПЕЧтПЁ АќЧб АЭРЬИч, ЛѓШЃРлПыШПАњ(interaction effect)ЖѓДТ АЭРК ДйИЅ ЕЖИГКЏМіРЧ
КЏШПЁ ЕћЖѓ Чб ЕЖИГКЏМіАЁ АсАњКЏМіПЁ ЙЬФЁДТ ПЕЧтПЁ АќЧб АЭРдДЯДй.
ПЙ
Чб ШИЛчПЁМДТ ШИЛчОїЙЋПЁ АќЗУЧЯПЉ ШИЛчОїЙЋ ЧтЛѓРЛ РЇЧиМДТ АЂ АГРЮКА РкОЦИИСЗЕЕПЭ АќЗУРЬ
РжДйАэ Л§АЂЧЯПЉ МККААњ ПЌЗЩПЁ ЕћИЅ РкОЦИИСЗЕЕИІ УјСЄЧЯАэРк ЧбДй.
ЁЁ
1) АЁМГМГСЄ
ЁЁ
<ПЌБИАЁМГ> :
1. МККАПЁ ЕћЖѓ РкОЦИИСЗЕЕПЁДТ ТїРЬАЁ РжДй.
2. ПЌЗЩПЁ ЕћЖѓ РкОЦИИСЗЕЕПЁДТ ТїРЬАЁ РжДй.
3. МККААњ ПЌЗЩАЃПЁДТ МЗЮ ЛѓШЃРлПыШПАњАЁ РжДй.
ЁЁ
1.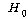 (ПЕАЁМГ): (ПЕАЁМГ):
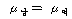
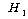 (ДыИГАЁМГ): (ДыИГАЁМГ):
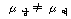
2.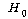 (ПЕАЁМГ): (ПЕАЁМГ):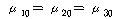
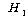 (ДыИГАЁМГ): (ДыИГАЁМГ):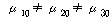
3.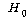 (ПЕАЁМГ):
ЛѓШЃРлПыШПАњАЁ ОјДй. (ПЕАЁМГ):
ЛѓШЃРлПыШПАњАЁ ОјДй.
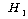 (ДыИГАЁМГ):
ЛѓШЃРлПыШПАњАЁ РжДй. (ДыИГАЁМГ):
ЛѓШЃРлПыШПАњАЁ РжДй.
2) РЏРЧМіСиМГСЄ
ЁЁ
3) АЫСЄХыАшЗЎ
ЁЁ
РЬПјКаЛъКаМЎЕЕ РЯПјКаЛъКаМЎАњ ИЖТљАЁСіЗЮ
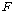 ХыАшЗЎ АЊРЬ
ЛчПыЕЫДЯДй. ХыАшЗЎ АЊРЬ
ЛчПыЕЫДЯДй. 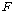 ХыАшЗЎРЧ
АшЛъРЛ РЇЧи КаЛъКаМЎРЬ ИеРњ МіЧрЕЧИч, РЬИІ РЇЧи ЕЖИГКЏМі ХыАшЗЎРЧ
АшЛъРЛ РЇЧи КаЛъКаМЎРЬ ИеРњ МіЧрЕЧИч, РЬИІ РЇЧи ЕЖИГКЏМі
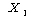 Ањ Ањ
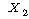 ЗЮ
ГЊДЉОюСјДйАэ АЁСЄЧеНУДй. РЬИІ ХыЧб УбКЏЗЎРК ДйРНАњ ААРЬ БИМКЕЫДЯДй. ЗЮ
ГЊДЉОюСјДйАэ АЁСЄЧеНУДй. РЬИІ ХыЧб УбКЏЗЎРК ДйРНАњ ААРЬ БИМКЕЫДЯДй.
ЁЁ
|
УбКЏЗЎ = ЕЖИГКЏМі
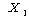 ПЁ
РЧЧб КЏЗЎ + ЕЖИГКЏМі ПЁ
РЧЧб КЏЗЎ + ЕЖИГКЏМі
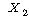 ПЁ
РЧЧб КЏЗЎ ПЁ
РЧЧб КЏЗЎ
+ ЕЮ ЕЖИГКЏМіПЁ РЧЧи МГИэЕЧСі ОЪРК КЏЗЎ |
АшЛъНФРК ДйРНАњ ААНРДЯДй.
ЁЁ
УбКЏЗЎ(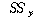 )
= )
= 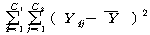
ЕЖИГКЏМі 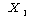 ПЁ
РЧЧб КЏЗЎ ( ПЁ
РЧЧб КЏЗЎ (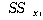 )
= )
= 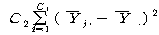
ЕЖИГКЏМі 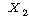 ПЁ
РЧЧб КЏЗЎ ( ПЁ
РЧЧб КЏЗЎ (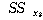 )
= )
= 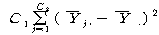
МГИэЕЧСі ОЪРК КЏЗЎ (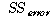 )
= )
= 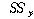 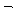 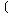 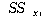 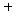 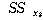 
ЁЁ
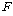 ХыАшЗЎРЧ
АшЛъРК РЇРЧ АшЛъРЛ ХфДыЗЮ РлМКЕШ КаЛъКаМЎЧЅИІ РЬПыЧЯПЉ БИЧв Мі РжНРДЯДй. ХыАшЗЎРЧ
АшЛъРК РЇРЧ АшЛъРЛ ХфДыЗЮ РлМКЕШ КаЛъКаМЎЧЅИІ РЬПыЧЯПЉ БИЧв Мі РжНРДЯДй.
ЁЁ
|
Source |
СІАіЧе(SS) |
РкРЏЕЕ df |
СІАіЦђБе(MS) |
F |
|
ЕЖИГКЏМі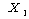 |
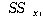 |
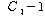 |
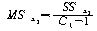 |
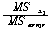 |
|
ЕЖИГКЏМі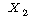 |
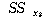 |
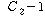 |
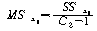 |
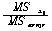 |
|
Error |
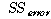 |
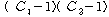 |
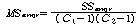 |
ЁЁ |
|
Total |
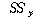 |
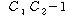 |
ЁЁ |
ЁЁ |
ЁЁ
АшЛъЕШ 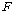 ХыАшЗЎ
АЊРЬ ХыАшРћРИЗЮ РЏРЧЧб СіИІ КИБт РЇЧиМДТ СЖЛчРкДТ ХыАшЗЎ
АЊРЬ ХыАшРћРИЗЮ РЏРЧЧб СіИІ КИБт РЇЧиМДТ СЖЛчРкДТ
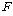 КаЦїЧЅПЁМ КаЦїЧЅПЁМ
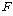 АЊРЧ
РгАшФЁИІ УЃОЦ АшЛъЕШ АЊРЧ
РгАшФЁИІ УЃОЦ АшЛъЕШ
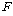 АЊАњ
КёБГЧЯПЉ АшЛъЕШ АЊАњ
КёБГЧЯПЉ АшЛъЕШ
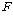 АЊРЬ АЊРЬ
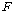 РгАшФЁКИДй
ХЋ АцПьПЁДТ ПЕАЁМГРЛ БтАЂЧв Мі РжНРДЯДй. РгАшФЁКИДй
ХЋ АцПьПЁДТ ПЕАЁМГРЛ БтАЂЧв Мі РжНРДЯДй.
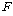 РгАшФЁ АЊРК РгАшФЁ АЊРК
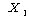 Ањ Ањ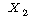 РЧ
РкРЏЕЕПЭ РЏРЧМіСи АЊРЛ ХыЧи КаЦїЧЅПЁМ УЃРИИщ ЕЫДЯДй. РЧ
РкРЏЕЕПЭ РЏРЧМіСи АЊРЛ ХыЧи КаЦїЧЅПЁМ УЃРИИщ ЕЫДЯДй.
ЁЁ
4) НЧЧрЧЯБт
ЁЁ
РЬПјКаЛъКаМЎРЛ НУРлЧЯБт РЇЧи
[ПЙСІ 9-3]ИІ
КвЗЏ ДйРНАњ ААРК Р§ТїИІ ЕћЖѓЧеДЯДй.
ЁЁ
|
КаМЎ(A)ЁцРЯЙнМБЧќИ№Чќ(G)ЁцРЯКЏЗЎ(U) |
ЁЁ
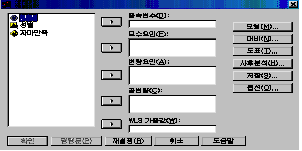
РЬ Р§ТїИІ ЕћИЃИщ [БзИВ 7.13]ПЭ ААРК ДыШЛѓРкАЁ ГЊХИГГДЯДй.
ЁЁ
ЁЁ
ДыШЛѓРкАЁ ГЊХИГЊИщ ПоТЪ КЏМіИёЗЯ УЂПЁ РжДТ КЏМі Сп СОМгКЏМіИІ СОМгКЏМі(D)ФРИЗЮ ЕЖИГКЏМіИІ
И№МіПфРЮ(F)ФРИЗЮ ПХБщДЯДй. БзЗБ ДйРН ДйОчЧб ПЩМЧЕщРЛ МБХУЧиОп ЧЯДТЕЅ РЬРќПЁ ЙшПю ЙЋРлРЇ
КэЗЯЕ№РкРЮПЁ РЧЧб РЯПјКаЛъКаМЎПЁМ ДйЗчОњРИЙЧЗЮ ПЉБтМДТ АЃДмШїИИ МГИэЧЯАкНРДЯДй.
ЁЁ
Јч И№Чќ(M)
ЁЁ
И№ЧќПЁМДТ ПЯРќПфРЮИ№ЧќАњ ЛчПыРкСЄРЧАЁ РжДТЕЅ РЬРќ РхПЁМ ЙшПю БтОяРЬ ГЊНУСв?
ПЯРќПфРЮИ№Чќ(A)ПЁМДТ КаМЎАсАњПЁ ЕЮ ЕЖИГКЏМіРЧ СжШПАњ, ЛѓШЃРлПыШПАњ, Р§Цэ ЕюРЬ ЦїЧдЕЧДТ
АЭРЬАэ, ЛчПыРкСЄРЧ(C)ПЁМДТ АЂ ЕЖИГКЏМіИЖДй ПјЧЯДТ ШПАњИІ ЛчПыРкАЁ НКНКЗЮ МГСЄЧЯДТ
АЭРдДЯДй.
ПЉБтМДТ ПЯРќПфРЮИ№ЧќРЛ МГСЄЧиЕЕ ЕЧАэ, ЛчПыРкСЄРЧИІ МГСЄЧЯЗСИщ ЕЮ ЕЖИГКЏРЮАЃПЁ ЛѓШЃРлПыРИЗЮ
МГСЄЧи СжИщ ЕЫДЯДй.
Јш ЛчШФКаМЎ(H)
ЁЁ
ЛчШФКаМЎПЁМДТ ПЌЗЩПЁ ДыЧб ДйСпКёБГИІ Чв Мі РжРИЙЧЗЮ ПЌЗЩПЁ ДыЧиМИИ ЛчШФАЫСѕРЛ ЧЯЕЕЗЯ
ЧеДЯДй. TukeyПЭ ScheffeИІ МГСЄЧЯПЉ КаМЎЧи КОНУДй.
ЁЁ
ПЩМЧ(O)ПЁМДТ БтМњХыАшЗЎИИРЛ МБХУЧб ШФ [АшМг]РЛ ДЉИЅ ДйРН [ШЎРЮ]РЛ ДЉИЃИщ ДйРНАњ ААРК
АсАњУЂРЬ ГЊХИГГДЯДй.
ЁЁ
-->АГУМ-АЃ
ПфРЮ
ЁЁ
|
|
КЏМіАЊ МГИэ |
N |
|
ПЌЗЩ |
1 |
20Ды |
6 |
|
2 |
30Ды |
6 |
|
3 |
40Ды РЬЛѓ |
6 |
|
МККА |
ГВ |
|
9 |
|
ПЉ |
|
9 |
АГУМАЃ ПфРЮЧЅПЁМДТ ПЌЗЩ Йз МККА КАЗЮ ФЩРЬНК МіАЁ ГЊХИГЊ РжНРДЯДй.
-->БтМњХыАшЗЎ
СОМгКЏМі: РкОЦИИСЗ
ЁЁ
|
ПЌЗЩ |
МККА |
ЦђБе |
ЧЅСиЦэТї |
N |
|
20Ды |
ГВ |
4.100 |
.200 |
3 |
|
ПЉ |
2.800 |
.265 |
3 |
|
ЧеАш |
3.450 |
.742 |
6 |
|
30Ды |
ГВ |
3.067 |
.252 |
3 |
|
ПЉ |
2.133 |
.208 |
3 |
|
ЧеАш |
2.600 |
.551 |
6 |
|
40Ды РЬЛѓ |
ГВ |
3.433 |
.208 |
3 |
|
ПЉ |
2.500 |
.200 |
3 |
|
ЧеАш |
2.967 |
.543 |
6 |
|
ЧеАш |
ГВ |
3.533 |
.492 |
9 |
|
ПЉ |
2.478 |
.349 |
9 |
|
ЧеАш |
3.006 |
.683 |
18 |
ПЌЗЩАњ МККАПЁ ЕћИЅ АЂ МПЕщРЧ ЦђБеАњ ЧЅСиЦэХИАЁ ГЊХИГЊ РжНРДЯДй.
ЁЁ
-->АГУМ-АЃ
ШПАњ АЫСЄ
СОМгКЏМі: РкОЦИИСЗ
ЁЁ
|
МвНК |
СІ III РЏЧќ СІАіЧе |
РкРЏЕЕ |
ЦђБеСІАі |
F |
РЏРЧШЎЗќ |
|
МіСЄ И№Чќ |
7.329(a) |
5 |
1.466 |
29.318 |
.000 |
|
Р§Цэ |
162.601 |
1 |
162.601 |
3252.011 |
.000 |
|
ПЌЗЩ |
2.181 |
2 |
1.091 |
21.811 |
.000 |
|
МККА |
5.014 |
1 |
5.014 |
100.278 |
.000 |
|
ПЌЗЩ * МККА |
.134 |
2 |
6.722E-02 |
1.344 |
.297 |
|
ПРТї |
.600 |
12 |
5.000E-02 |
|
|
|
ЧеАш |
170.530 |
18 |
|
|
|
|
МіСЄ ЧеАш |
7.929 |
17 |
|
|
|
|
a R СІАі = .924 (МіСЄЕШ R СІАі = .893) |
ЁЁ
АГУМАЃ ШПАњАЫСЄПЁМДТ МККААњ ПЌЗЩПЁ ЕћИЅ РкОЦИИСЗЕЕПЁ АќЧб СжШПАњПЭ ЛѓШЃРлПыШПАњРЧ АсАњАЁ
ГЊХИГЊ РжНРДЯДй.
1. ПЌЗЩПЁ ДыЧб СжШПАњИІ КИИщ
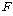 =21.811,
РЏРЧШЎЗќРК .000РИЗЮ (ПЕАЁМГ): =21.811,
РЏРЧШЎЗќРК .000РИЗЮ (ПЕАЁМГ):
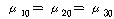 ДТ
РЏРЧМіСи 0.01ПЁМ БтАЂЕЩ Мі РжНРДЯДй. ЕћЖѓМ ПЌЗЩПЁ ЕћИЅ РкОЦИИСЗЕЕПЁДТ ТїРЬАЁ РжДйАэ
АсЗаСіРЛ Мі РжНРДЯДй. ДТ
РЏРЧМіСи 0.01ПЁМ БтАЂЕЩ Мі РжНРДЯДй. ЕћЖѓМ ПЌЗЩПЁ ЕћИЅ РкОЦИИСЗЕЕПЁДТ ТїРЬАЁ РжДйАэ
АсЗаСіРЛ Мі РжНРДЯДй.
2. МККАПЁ ДыЧб СжШПАњИІ КИИщ
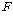 =100.278,
РЏРЧШЎЗќРК .000РИЗЮ =100.278,
РЏРЧШЎЗќРК .000РИЗЮ
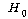 (ПЕАЁМГ): (ПЕАЁМГ):
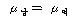 ИІ РЏРЧМіСи
0.01ПЁМ БтАЂЕЩ Мі РжНРДЯДй. ЕћЖѓМ МККАПЁ ЕћИЅ РкОЦИИСЗЕЕПЁДТ ТїРЬАЁ РжДйАэ АсЗаСіРЛ Мі
РжНРДЯДй. ИІ РЏРЧМіСи
0.01ПЁМ БтАЂЕЩ Мі РжНРДЯДй. ЕћЖѓМ МККАПЁ ЕћИЅ РкОЦИИСЗЕЕПЁДТ ТїРЬАЁ РжДйАэ АсЗаСіРЛ Мі
РжНРДЯДй.
3. ЛѓШЃРлПыШПАњИІ КИИщ
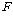 =1.344,
РЏРЧШЎЗќРК .297РИЗЮ =1.344,
РЏРЧШЎЗќРК .297РИЗЮ
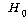 (ПЕАЁМГ):
ЛѓШЃРлПыШПАњАЁ ОјДйДТ БтАЂЕЩ Мі ОјРИЙЧЗЮ МККААњ ПЌЗЩРК ЛѓШЃРлПыШПАњАЁ ОјДТ АЭРИЗЮ АсЗаСіРЛ Мі
РжНРДЯДй. (ПЕАЁМГ):
ЛѓШЃРлПыШПАњАЁ ОјДйДТ БтАЂЕЩ Мі ОјРИЙЧЗЮ МККААњ ПЌЗЩРК ЛѓШЃРлПыШПАњАЁ ОјДТ АЭРИЗЮ АсЗаСіРЛ Мі
РжНРДЯДй.
ЁЁ
ЛчШФАЫСЄ
ПЌЗЩ
-->ДйСп
КёБГ
СОМгКЏМі: РкОЦИИСЗ
ЁЁ
|
|
ЦђБеТї
(I-J) |
ЧЅСи
ПРТї |
РЏРЧ
ШЎЗќ |
95% НХЗкБИАЃ |
|
|
(I) ПЌЗЩ |
(J) ПЌЗЩ |
ЧЯЧбАЊ |
ЛѓЧбАЊ |
|
Tukey HSD |
20Ды |
30Ды |
.850(*) |
.132 |
.000 |
.504 |
1.196 |
|
40Ды РЬЛѓ |
.483(*) |
.132 |
.007 |
.137 |
.829 |
|
30Ды |
20Ды |
-.850(*) |
.132 |
.000 |
-1.196 |
-.504 |
|
40Ды РЬЛѓ |
-.367(*) |
.132 |
.037 |
-.713 |
-.020 |
|
40Ды РЬЛѓ |
20Ды |
-.483(*) |
.132 |
.007 |
-.829 |
-.137 |
|
30Ды |
.367(*) |
.132 |
.037 |
.020 |
.713 |
|
Scheffe |
20Ды |
30Ды |
.850(*) |
.132 |
.000 |
.488 |
1.212 |
|
40Ды РЬЛѓ |
.483(*) |
.132 |
.009 |
.122 |
.845 |
|
30Ды |
20Ды |
-.850(*) |
.132 |
.000 |
-1.212 |
-.488 |
|
40Ды РЬЛѓ |
-.367(*) |
.132 |
.047 |
-.728 |
-.005 |
|
40Ды РЬЛѓ |
20Ды |
-.483(*) |
.132 |
.009 |
-.845 |
-.122 |
|
30Ды |
.367(*) |
.132 |
.047 |
.005 |
.728 |
|
АќУјЕШ ЦђБеПЁ БтУЪЧеДЯДй. |
|
* .05 МіСиПЁМ ЦђБеТїДТ РЏРЧЧеДЯДй. |
ЁЁ
ЛчШФАЫСЄ ЧЅПЁМДТ ПЌЗЩПЁ АќЧб ММ С§ДмРЧ ЛчШФАЫСѕАсАњИІ КИПЉСнДЯДй. 10Ды, 20Ды, 30Ды
И№ЕЮДТ КёБГЧи КЛ АсАњ Бз ТїРЬАЁ РЏРЧЧЯАд ГЊХИГЕНРДЯДй. РЏРЧШЎЗќ АЊРЛ ЛьЦьКИИщ TukeyРЧ
АЊРЬ ScheffeАЊКИДй РлРК АЭРЛ ОЫ Мі РжНРДЯДй. РЬ АсАњДТ TukeyАЁ ScheffeКИДй
КИМіРћРЬЖѓДТ АЭРЛ ОЫАд ЧиСжИч, МПРЧ ХЉБтАЁ ААРК АцПьПЁДТ Tukey ЙцЙ§РЛ ОВДТ АЭРЬ Дѕ
СЄЙаЧЯАд ГЊПТДйДТ АЭРЛ ОЫ Мі РжНРДЯДй.
ЁЁ
ЕПРЯС§ДмБК
РкОЦИИСЗ
-->
|
|
N |
С§ДмБК |
|
|
ПЌЗЩ |
1 |
2 |
3 |
|
Tukey HSD(a,b) |
30Ды |
6 |
2.600 |
|
|
|
40Ды РЬЛѓ |
6 |
|
2.967 |
|
|
20Ды |
6 |
|
|
3.450 |
|
РЏРЧШЎЗќ |
|
1.000 |
1.000 |
1.000 |
|
Scheffe(a,b) |
30Ды |
6 |
2.600 |
|
|
|
40Ды РЬЛѓ |
6 |
|
2.967 |
|
|
20Ды |
6 |
|
|
3.450 |
|
РЏРЧШЎЗќ |
|
1.000 |
1.000 |
1.000 |
ЁЁ
ЕПРЯС§ДмБК ЧЅИІ КИИщ ПЌЗЩПЁ ЕћИЅ РкОЦИИСЗЕЕПЁ АќЧб TukeyПЭ ScheffeРЧ С§ДмАсАњФЁАЁ
ГЊХИГГДЯДй. С§Дм 1, 2, 3ПЁМ АЊЕщРЛ КИИщ ДйЕщ С§ДмРЬ ДйИЃДйДТ АЭРЛ ОЫ Мі РжНРДЯДй.
ИИРЯ С§Дм 2ПЭ 3РЬ ЕПРЯЧб РЇФЁПЁ АЊРЬ ГЊХИГЊ РжДйИщ С§Дм2ПЭ 3РК ЕПРЯЧб С§ДмБКРЬЖѓАэ
Л§АЂЧЯНУИщ ЕЫДЯДй. ПЉБтМДТ ЕПРЯЧб РЇФЁПЁ РжДТ АЊРЬ ОјРИЙЧЗЮ С§ДмАЃПЁДТ МЗЮ ЕПРЯЧЯСі ОЪДйАэ
КаМЎЧЯНУИщ ЕЫДЯДй.
-->
ЁЁ |