|
8.2 ҙЩәҜ·®әР»кәРј®(MANOVA)
7АеҝЎјӯ әёёй өО БэҙЬ АМ»уАЗ ЖтұХА» әсұіЗПұв А§ЗШјӯҙВ ANOVAёҰ АМҝлЗСҙЩ°н №иҝьҪАҙПҙЩ.
ANOVAҙВ БҫјУәҜјц°Ў 1°іАО №ЭёйҝЎ MANOVAҙВ БҫјУәҜјц°Ў 2°іАО °жҝмјј БэҙЬЖтұХөйАЗ
ВчАМёҰ әсұіЗПҙВөҘ »зҝлЗХҙПҙЩ. ө¶ёіәҜјцҙВ ёнёсГҙөөАМ°н БҫјУәҜјцҙВ °Ј°ЭГҙөө АМ»уАё·О ұёјәөЗҫоҫЯ
ЗХҙПҙЩ.
ЎЎ
<ANOVAҝН MANOVAАЗ ВчАМБЎ>
Ёз MANOVAҙВ БҫјУәҜјцАЗ Б¶ЗХҝЎ ҙлЗС Иҝ°ъАЗ өҝҪГ°ЛБӨА» БЯҝдҪГЗХҙПҙЩ. Бп ҙләОәРАЗ
БҫјУәҜјцөйАә јӯ·О »у°ь°ь°и°Ў АЦұв ¶§№®АФҙПҙЩ. өы¶ујӯ MANOVAҙВ ANOVAҝНҙВ ҙЮё®
БэҙЬ°ЈАЗ °бЗХөИ ВчАМёҰ №аЗфіҫ јц АЦҫо БэҙЬ°ЈАЗ ВчАМёҰ №аИчҙВөҘ »зҝл°ЎҙЙЗС БӨәёёҰ әёҙЩ ё№АМ
»зҝлЗТ јц АЦҪАҙПҙЩ.
Ёи MANOVA јі°иАЗ ЖҜВЎАә БҫјУәҜјц°Ў әӨЕНәҜјц¶уҙВ БЎАФҙПҙЩ.
Ёй ANOVA·О ҝ©·Ҝ °іАЗ БҫјУәҜјцёҰ Жт°ЎЗП·Бёй, ҝ©·Ҝ№шАЗ әРј®А» ЗШҫЯ ЗПБцёё, MANOVAҙВ
ҙЬ ЗС№шАЗ әРј®ёёА» ЗП°Ф өЛҙПҙЩ. өы¶ујӯ ANOVA·О әРј®ЗП°Ф өЗёй, 1Бҫ ҝАВчАЗ И®·ьАМ
ДҝБэҙПҙЩ.
<°ЎБӨ>
Ёз °ьГшДЎ°Ў јӯ·О ө¶ёіАыАМҙЩ.
Ёи °ў БэҙЬАЗ әР»к°ъ °шәР»к За·ДАМ өҝАПЗПҙЩ.
Ёй ёрөз БҫјУәҜјцөйАә ҙЩәҜ·® БӨұФәРЖчёҰ өыёҘҙЩ.
ЎЎ
<әРј®АэВч>
Ёз ёХАъ БҫјУәҜјц »зАМҝЎјӯ »у°ь°ь°и°Ў АЦҙВБцАЗ ҝ©әОёҰ Б¶»зЗХҙПҙЩ. »у°ь°ь°и°Ў ҫшАёёй ANOVAёҰ
ҪЗҪГЗП°н, »у°ь°ь°и°Ў АЦАёёй, MANOVAёҰ ҪЗҪГЗХҙПҙЩ.
Ёи әҜјцөйАЗ ұвә»°ЎБӨАО ҙЩәҜ·® БӨұФәРЖчјә°ъ өоәР»кјә өоА» Б¶»зЗХҙПҙЩ.
Ёй ёрөз ҝдАО јцБШАЗ ЖтұХ әӨЕНөйАМ өҝАПЗСБцёҰ °ЛБӨЗХҙПҙЩ.
Ёк ёёАП ёрөз ЖтұХ әӨЕНөйАМ °°ҙЩҙВ ҝө°ЎјіАМ ГӨЕГөЗёй, °ЛБӨАә ҙх АМ»у БшЗаөЗБц ҫК°н °Еұвјӯ
іЎАМ ііҙПҙЩ.
Ёл ёёАП ҙлёі°ЎјіАМ ГӨЕГөЗёй, әҜјцөйА» °іә°АыАё·О Б¶»зЗПҝ© ҫо¶І әҜјц°Ў ҫуё¶іӘ ҙЩёҘ°Ў, ұЧё®°н
ұЧ ВчАМ°Ў АЗ№МЗПҙВ °НАә №«ҫщАО°ЎёҰ ұФёнЗШҫЯ ЗХҙПҙЩ.
ЎЎ
ҝ№
ЗРівҝЎ өы¶у ЗРҪАИҝ°ъ°Ў ҙЩёҘБцёҰ Б¶»зЗПұв А§ЗШ, ЗРівҝЎ өы¶у јцҫчЕВөө, ЗРҪАЕВөө, ЗРҪАёёБ·өөёҰ
Б¶»зЗПұв·О ЗПҝҙҙЩ.
ЎЎ
1) БҫјУәҜјц°ЈАЗ »у°ь°ь°и ГшБӨ
ЎЎ
(1) °ЎјіјіБӨ
ЎЎ
<ҝ¬ұё№®БҰ> : јј °ЎБц ЗРҪАИҝ°ъ(јцҫчЕВөө, ЗРҪАЕВөө, ЗРҪАёёБ·өө)ҙВ јӯ·О ВчАМ°Ў АЦҙЩ.
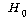 (ҝө°Ўјі)
: јј °ЎБц ЗРҪАИҝ°ъҙВ ВчАМ°Ў ҫшҙЩ. (ҝө°Ўјі)
: јј °ЎБц ЗРҪАИҝ°ъҙВ ВчАМ°Ў ҫшҙЩ.
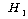 (ҙлёі°Ўјі)
: јј °ЎБц ЗРҪАИҝ°ъҙВ ВчАМ°Ў АЦҙЩ. (ҙлёі°Ўјі)
: јј °ЎБц ЗРҪАИҝ°ъҙВ ВчАМ°Ў АЦҙЩ.
ЎЎ
(2) АҜАЗјцБШјіБӨ
(3) ҪЗЗа№ж№э
БҫјУәҜјцөй °ЈАЗ »у°ь°ь°иёҰ ҫЛҫЖәёұв А§ЗШ
[ҝ№БҰ 10-2]ёҰ
әТ·Ҝ ҙЩАҪ°ъ °°Аә АэВчёҰ өы¶уЗХҙПҙЩ.
ЎЎ
|
әРј®(A)Ўж»у°ьәРј®(C)ЎжАМәҜ·® »у°ь°ијц(B) |
әҜјцёс·П ДӯҝЎ АЦҙВ әҜјцөй БЯ БҫјУәҜјцөйА» әҜјц(V)·О ҝЕ°ЬБШ ИД өо°ЈГҙөө АМ»уАМ№З·О
PearsonАЗ »у°ь°ијцёҰ јіБӨЗШ БШ ИД [И®АО]А» ҙ©ёЈёй ҙЩАҪ°ъ °°Аә °б°ъ ГўАМ іӘЕёііҙПҙЩ.
-->»у°ь°ијц
ЎЎ
|
|
јцҫчЕВөө |
ЗРҪАЕВөө |
ЗРҪАёёБ· |
|
јцҫчЕВөө |
Pearson »у°ь°ијц |
1.000 |
.753(**) |
.665(**) |
|
АҜАЗИ®·ь (ҫзВК) |
. |
.000 |
.003 |
|
N |
18 |
18 |
18 |
|
ЗРҪАЕВөө |
Pearson »у°ь°ијц |
.753(**) |
1.000 |
.682(**) |
|
АҜАЗИ®·ь (ҫзВК) |
.000 |
. |
.002 |
|
N |
18 |
18 |
18 |
|
ЗРҪАёёБ· |
Pearson »у°ь°ијц |
.665(**) |
.682(**) |
1.000 |
|
АҜАЗИ®·ь (ҫзВК) |
.003 |
.002 |
. |
|
N |
18 |
18 |
18 |
|
** »у°ь°ијцҙВ 0.01 јцБШ(ҫзВК)ҝЎјӯ АҜАЗЗХҙПҙЩ. |
ЎЎ
»у°ь°ијц ЗҘҝЎјӯҙВ јј °іАЗ БҫјУәҜјцөй °ЈАЗ »у°ь°ь°и БӨөөёҰ іӘЕёі» БЭҙПҙЩ. АМ ЗҘёҰ »мЖмәёёй,
јј °іАЗ БҫјУәҜјцөйАә ёрөО ҫзАЗ »у°ь°ь°и°Ў АЦҙЩҙВ °НА» ҫЛ јц АЦҪАҙПҙЩ. өы¶ујӯ MANOVAҝЎ
АЗЗС әРј®А» ЗШҫЯЗСҙЩҙВ °НА» ҫЛ јц АЦҪАҙПҙЩ.
ЎЎ
2) ҙЩәҜ·® әР»кәРј®(MANOVA) ҪЗЗа
ЎЎ
ҙЩәҜ·® әР»кәРј®А» ҪЗЗаЗПұв А§ЗШ ҙЩАҪ°ъ °°Аә АэВчёҰ өыёЁҙПҙЩ.
ЎЎ
|
әРј®(A)ЎжАП№ЭјұЗьёрЗь(G)ЎжҙЩәҜ·®(U) |
АМ АэВчёҰ өыёЈёй [ұЧёІ 8.4]ҝН °°Аә ҙлИӯ»уАЪ°Ў іӘЕёііҙПҙЩ.
ЎЎ
Ёз, Ёи ҝЮВК әҜјцёс·П ДӯҝЎ АЦҙВ әҜјцөй БЯ БҫјУәҜјцёҰ БҫјУәҜјц(D)ДӯАё·О, ө¶ёіәҜјцёҰ
ёрјцҝдАО(F)ДӯАё·О ҝЕұйҙПҙЩ.
Ёй ёрЗь(M)
ұвә»Аё·О јіБӨөЗҫо АЦҙВ ҝПБӨёрЗьҝдАО°ъ БҰ ҘІ АҜЗьАё·О јіБӨЗШ БЭҙПҙЩ. ёрЗьҝЎ ҙлЗС і»ҝлАә
әР»кәРј®ҝЎјӯ Вь°нЗПјјҝд.
ЎЎ
Ёк ҙләс(N), өөЗҘ(T)
АМ °НАә ұвә»јіБӨ »уЕВёҰ АҜБцЗШ БЭҙПҙЩ.
ЎЎ
Ёл »зИДәРј®(H)
[ҝдАО(F)]ҝЎ АЦҙВ әҜјцёҰ Е¬ёҜЗПҝ© ҝАёҘВКҝЎ АЦҙВ [»зИД°ЛБӨәҜјц(P)]·О ҝЕ°ЬБШ ИД јҝАЗ
Е©ұв°Ў °°Аё№З·О Tukey №ж№э(T)ёҰ јұЕГЗШ БЭҙПҙЩ.
ЎЎ
Ём ҝЙјЗ(O)
ҝЙјЗҝЎјӯҙВ °б°ъ ГўҝЎ БҰҪГЗТ Гв·В°б°ъёҰ јіБӨЗШ БЭҙПҙЩ. ҝ©ұвјӯҙВ ұвјъЕл°и·®°ъ өҝБъјә°ЛБӨёёА»
јіБӨЗШ БШ ИД [°ијУ]А» ҙ©ёЁҙПҙЩ.
ЎЎ
АМ °ъБӨАМ іЎіӯ ИД [И®АО]А» ҙ©ёЈёй ҙЩАҪ°ъ °°Аә °б°ъ ГўАМ іӘЕёііҙПҙЩ.
-->°іГј-°Ј
ҝдАО
ЎЎ
°іГј°Ј ҝдАО ЗҘҝЎјӯҙВ °ў ЗРівә°·О »з·Кјц°Ў іӘЕёіӘ АЦҪАҙПҙЩ.
ЎЎ
-->ұвјъЕл°и·®
ЎЎ
|
|
ЗРів |
ЖтұХ |
ЗҘБШЖнВч |
N |
|
јцҫчЕВөө |
1 |
4.33 |
.82 |
6 |
|
2 |
1.67 |
.52 |
6 |
|
3 |
3.00 |
1.41 |
6 |
|
ЗХ°и |
3.00 |
1.46 |
18 |
|
ЗРҪАЕВөө |
1 |
3.33 |
1.03 |
6 |
|
2 |
1.83 |
.75 |
6 |
|
3 |
3.00 |
1.10 |
6 |
|
ЗХ°и |
2.72 |
1.13 |
18 |
|
ЗРҪАёёБ· |
1 |
2.67 |
.52 |
6 |
|
2 |
2.00 |
.63 |
6 |
|
3 |
2.50 |
.55 |
6 |
|
ЗХ°и |
2.39 |
.61 |
18 |
ЎЎ
ұвјъЕл°и·® ЗҘҝЎјӯҙВ ө¶ёіәҜјцҝЎ өыёҘ БҫјУәҜјцАЗ ЖтұХ°ъ ЗҘБШЖнВч, »з·Кјц°Ў БҰҪГөЗҫо АЦҪАҙПҙЩ.
ЎЎ
-->°шәР»кЗа·ДҝЎ
ҙлЗС BoxАЗ өҝАПјә °ЛБӨ(a)
ЎЎ
|
BoxАЗ M |
16.478 |
|
F |
.961 |
|
АЪАҜөө1 |
12 |
|
АЪАҜөө2 |
1090.385 |
|
АҜАЗИ®·ь |
.484 |
|
ҝ©·Ҝ БэҙЬҝЎјӯ БҫјУәҜјцАЗ °ьГш °шәР»кЗа·ДАМ өҝАПЗС ҝө°ЎјіА» °ЛБӨЗХҙПҙЩ. |
|
a °иИ№: Intercept+ЗРів |
өҝАПјә °ЛБӨ ЗҘҝЎјӯҙВ јј БэҙЬАЗ °шәР»к За·ДАМ өҝАПЗПҙЩҙВ °ЎБӨҝЎ ҙлЗС °ЛБх°б°ъ°Ў БҰҪГөЗҫо
АЦҪАҙПҙЩ. АҜАЗИ®·ьАМ .484АМ№З·О ҝө°Ўјі(°шәР»кЗа·ДАМ өҝАПЗПҙЩ)А» ұв°ўЗПБц ёшЗП№З·О
°шәР»кЗа·ДАЗ өҝАПјә °ЎБӨҝЎ №®БҰ°Ў ҫшҙЩ°н °б·РБцА» јц АЦҪАҙПҙЩ.
ЎЎ
-->ҙЩәҜ·®
°ЛБӨ(c)
ЎЎ
|
Иҝ°ъ |
°Ә |
F |
°Ўјі АЪАҜөө |
ҝАВч АЪАҜөө |
АҜАЗИ®·ь |
|
Intercept |
PillaiАЗ Ж®·№АМҪә |
.957 |
95.908(a) |
3.000 |
13.000 |
.000 |
|
WilksАЗ ¶чҙЩ |
.043 |
95.908(a) |
3.000 |
13.000 |
.000 |
|
HotellingАЗ Ж®·№АМҪә |
22.133 |
95.908(a) |
3.000 |
13.000 |
.000 |
|
RoyАЗ ГЦҙлұЩ |
22.133 |
95.908(a) |
3.000 |
13.000 |
.000 |
|
ЗРів |
PillaiАЗ Ж®·№АМҪә |
.679 |
2.396 |
6.000 |
28.000 |
.054 |
|
WilksАЗ ¶чҙЩ |
.370 |
2.793(a) |
6.000 |
26.000 |
.031 |
|
HotellingАЗ Ж®·№АМҪә |
1.574 |
3.147 |
6.000 |
24.000 |
.020 |
|
RoyАЗ ГЦҙлұЩ |
1.486 |
6.933(b) |
3.000 |
14.000 |
.004 |
|
a БӨИ®ЗС Ел°и·® |
|
b ЗШҙз АҜАЗјцБШҝЎјӯ ЗПЗС°ӘА» №Я»эЗПҙВ Ел°и·®Аә FҝЎјӯ »уЗС°ӘАФҙПҙЩ. |
|
c °иИ№: Intercept+ЗРів |
ЎЎ
ҙЩәҜ·® °ЛБх ЗҘҝЎјӯҙВ ЗРівҝЎ өыёҘ ҙЩәҜ·® °ЛБх °б°ъ°Ў БҰҪГөЗҫо АЦҪАҙПҙЩ. АҜАЗИ®·ьА» әёҫТА» ¶§
PillaiАЗ ¶чҙЩҝЎјӯёё АҜАЗЗПБц ҫКА» »У ҙЩёҘ әОәРҝЎјӯҙВ ёрөО ұв°ўЗТ јц АЦАё№З·О Аь№ЭАыАё·О
ҝө°Ўјі(јј °ЎБц ЗРҪАИҝ°ъҙВ ВчАМ°Ў ҫшҙЩ)ёҰ ұв°ўЗТ јц АЦҪАҙПҙЩ. өы¶ујӯ јј °ЎБц ЗРҪАИҝ°ъҙВ
ВчАМ°Ў АЦҙЩ°н °б·РБцА» јц АЦҪАҙПҙЩ.
ЎЎ
-->ҝАВч
әР»кАЗ өҝАПјәҝЎ ҙлЗС LeveneАЗ °ЛБӨ(a)
ЎЎ
|
|
F |
АЪАҜөө1 |
АЪАҜөө2 |
АҜАЗИ®·ь |
|
јцҫчЕВөө |
1.462 |
2 |
15 |
.263 |
|
ЗРҪАЕВөө |
.185 |
2 |
15 |
.833 |
|
ЗРҪАёёБ· |
.437 |
2 |
15 |
.654 |
|
ҝ©·Ҝ БэҙЬҝЎјӯ БҫјУәҜјцАЗ ҝАВч әР»кАМ өҝАПЗС ҝө°ЎјіА» °ЛБӨЗХҙПҙЩ. |
|
a °иИ№: Intercept+ЗРів |
ҝАВчәР»кАЗ өҝАПјәҝЎ ҙлЗС LeveveАЗ °ЛБӨ ЗҘҝЎјӯҙВ БҫјУәҜјцөйАЗ әР»кАЗ өҝБъјә °ЎБӨҝЎ ҙлЗС
°ЛБх°б°ъ°Ў іӘЕёіӘ АЦҪАҙПҙЩ. °ў БҫјУәҜАОАЗ АҜАЗИ®·ьАМ ёрөО 0.05АМ»уАё·О ҝө°ЎјіА» ұв°ўЗПБц
ёшЗП№З·О БэҙЬАЗ өоәР»к °ЎБӨҝЎҙВ №®БҰ°Ў ҫшҙЩ°н °б·РБцА» јц АЦҪАҙПҙЩ.
ЎЎ
-->°іГј-°Ј
Иҝ°ъ °ЛБӨ
ЎЎ
|
јТҪә |
БҫјУәҜјц |
БҰ III АҜЗь БҰ°цЗХ |
АЪАҜөө |
ЖтұХБҰ°ц |
F |
АҜАЗИ®·ь |
|
јцБӨ ёрЗь |
јцҫчЕВөө |
21.333(a) |
2 |
10.667 |
10.909 |
.001 |
|
ЗРҪАЕВөө |
7.444(b) |
2 |
3.722 |
3.941 |
.042 |
|
ЗРҪАёёБ· |
1.444(c) |
2 |
.722 |
2.241 |
.141 |
|
Intercept |
јцҫчЕВөө |
162.000 |
1 |
162.000 |
165.682 |
.000 |
|
ЗРҪАЕВөө |
133.389 |
1 |
133.389 |
141.235 |
.000 |
|
ЗРҪАёёБ· |
102.722 |
1 |
102.722 |
318.793 |
.000 |
|
ЗРів |
јцҫчЕВөө |
21.333 |
2 |
10.667 |
10.909 |
.001 |
|
ЗРҪАЕВөө |
7.444 |
2 |
3.722 |
3.941 |
.042 |
|
ЗРҪАёёБ· |
1.444 |
2 |
.722 |
2.241 |
.141 |
|
ҝАВч |
јцҫчЕВөө |
14.667 |
15 |
.978 |
|
|
|
ЗРҪАЕВөө |
14.167 |
15 |
.944 |
|
|
|
ЗРҪАёёБ· |
4.833 |
15 |
.322 |
|
|
|
ЗХ°и |
јцҫчЕВөө |
198.000 |
18 |
|
|
|
|
ЗРҪАЕВөө |
155.000 |
18 |
|
|
|
|
ЗРҪАёёБ· |
109.000 |
18 |
|
|
|
|
јцБӨ ЗХ°и |
јцҫчЕВөө |
36.000 |
17 |
|
|
|
|
ЗРҪАЕВөө |
21.611 |
17 |
|
|
|
|
ЗРҪАёёБ· |
6.278 |
17 |
|
|
|
|
a R БҰ°ц = .593 (јцБӨөИ R БҰ°ц = .538) |
|
b R БҰ°ц = .344 (јцБӨөИ R БҰ°ц = .257) |
|
c R БҰ°ц = .230 (јцБӨөИ R БҰ°ц = .127) |
ЎЎ
°іГј-°Ј Иҝ°ъ °ЛБх ЗҘҝЎјӯҙВ ЗРҪАИҝ°ъҝЎ ҙлЗШ әРј®ЗС °б°ъ°Ў БҰҪГөЗҫо АЦҪАҙПҙЩ. АМ ЗҘёҰ ЕлЗШ
ҙЩАҪ°ъ °°Аә ҝ¬ұё№®БҰёҰ БҰұвЗТ јц АЦҪАҙПҙЩ.
ЎЎ
<ҝ¬ұё№®БҰ>
1. јцҫчЕВөөҙВ ЗРівҝЎ өы¶у өҝАПЗПБц ҫКҙЩ.
2. ЗРҪАЕВөөҙВ ЗРівҝЎ өы¶у өҝАПЗПБц ҫКҙЩ.
3. ЗРҪАёёБ·өөҙВ ЗРівҝЎ өы¶у өҝАПЗПБц ҫКҙЩ.
ЎЎ
А§АЗ ЗҘҝЎјӯ іӘҝВ °б°ъҝЎјӯ ЗРівҝЎ өыёҘ јцҫчЕВөөАЗ АҜАЗИ®·ьАә .001Аё·О АҜАЗ№МЗС °ӘАМ
іӘҝФАё№З·О ҝө°Ўјі(јцҫчЕВөөҙВ ЗРівҝЎ өы¶у ёрөО өҝАПЗПҙЩ.
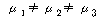 )А»
ұв°ўЗП№З·О, јцҫчЕВөөҙВ ЗРівҝЎ өы¶у өҝАПЗПБц ҫКҙЩ°н °б·РБцА» јц АЦҪАҙПҙЩ. )А»
ұв°ўЗП№З·О, јцҫчЕВөөҙВ ЗРівҝЎ өы¶у өҝАПЗПБц ҫКҙЩ°н °б·РБцА» јц АЦҪАҙПҙЩ.
ЗРівҝЎ өыёҘ ЗРҪАЕВөөАЗ АҜАЗИ®·ьАә .042·О АҜАЗ№МЗС °ӘАМ іӘҝФАё№З·О ҝө°Ўјі(ЗРҪАЕВөөҙВ ЗРівҝЎ
өы¶у ёрөО өҝАПЗПҙЩ)А» ұв°ўЗП№З·О, ЗРҪАЕВөөҙВ ЗРівҝЎ өы¶у өҝАПЗПБц ҫКҙЩ°н °б·РБцА» јц
АЦҪАҙПҙЩ.
ЗРівҝЎ өыёҘ ЗРҪАёёБ·өөАЗ АҜАЗИ®·ьАә .141Аё·О АҜАЗ№МЗС °ӘАМ ҫЖҙП№З·О ҝө°Ўјі(ЗРҪАёёБ·өөҙВ
ЗРівҝЎ өы¶у ёрөО өҝАПЗПҙЩ)ёҰ ұв°ўЗПБц ёшЗП№З·О, ЗРҪАёёБ·өөҙВ ЗРівҝЎ өы¶у ёрөО өҝАПЗПҙЩ°н
°б·РБцА» јц АЦҪАҙПҙЩ.
ЎЎ
ё¶Бцё·Аё·О, °ў°ўАЗ ЗРҪАИҝ°ъ(јцҫчЕВөө, ЗРҪАЕВөө, ЗРҪАёёБ·өө)АЗ °ӘАә ұёГјАыАё·О ҫоҙА БэҙЬ°ъ
ВчАМ°Ў АЦҙВБц ҫЛҫЖәёұв А§ЗШјӯҙВ »зИД°ЛБх °б°ъёҰ »мЖмәёҫЖҫЯ ЗХҙПҙЩ.
ЎЎ
»зИД°ЛБӨ / ЗРів/ -->ҙЩБЯ әсұі/ Tukey
HSD
ЎЎ
|
|
ЖтұХВч
(I-J) |
ЗҘБШ
ҝАВч |
АҜАЗ
И®·ь |
95% ҪЕ·Ъұё°Ј |
|
БҫјУәҜјц |
(I) ЗРів |
(J) ЗРів |
ЗПЗС°Ә |
»уЗС°Ә |
|
јцҫчЕВөө |
1 |
2 |
2.67(*) |
.57 |
.001 |
1.18 |
4.15 |
|
3 |
1.33 |
.57 |
.081 |
-.15 |
2.82 |
|
2 |
1 |
-2.67(*) |
.57 |
.001 |
-4.15 |
-1.18 |
|
3 |
-1.33 |
.57 |
.081 |
-2.82 |
.15 |
|
3 |
1 |
-1.33 |
.57 |
.081 |
-2.82 |
.15 |
|
2 |
1.33 |
.57 |
.081 |
-.15 |
2.82 |
|
ЗРҪАЕВөө |
1 |
2 |
1.50(*) |
.56 |
.043 |
4.26E-02 |
2.96 |
|
3 |
.33 |
.56 |
.825 |
-1.12 |
1.79 |
|
2 |
1 |
-1.50(*) |
.56 |
.043 |
-2.96 |
-4.26E-02 |
|
3 |
-1.17 |
.56 |
.128 |
-2.62 |
.29 |
|
3 |
1 |
-.33 |
.56 |
.825 |
-1.79 |
1.12 |
|
2 |
1.17 |
.56 |
.128 |
-.29 |
2.62 |
|
ЗРҪАёёБ· |
1 |
2 |
.67 |
.33 |
.138 |
-.18 |
1.52 |
|
3 |
.17 |
.33 |
.868 |
-.68 |
1.02 |
|
2 |
1 |
-.67 |
.33 |
.138 |
-1.52 |
.18 |
|
3 |
-.50 |
.33 |
.307 |
-1.35 |
.35 |
|
3 |
1 |
-.17 |
.33 |
.868 |
-1.02 |
.68 |
|
2 |
.50 |
.33 |
.307 |
-.35 |
1.35 |
|
°ьГшөИ ЖтұХҝЎ ұвГКЗХҙПҙЩ. |
|
* .05 јцБШҝЎјӯ ЖтұХВчҙВ АҜАЗЗХҙПҙЩ. |
»зИД°ЛБӨ ЗҘҝЎјӯҙВ °ў БҫјУәҜјцә°·О ҫоҙА БэҙЬөй °ЈҝЎ ВчАМ°Ў АЦҙВБцёҰ »зИД°ЛБхЗС °б°ъ°Ў БҰҪГөЗҫо
АЦҪАҙПҙЩ.
јцҫчЕВөөҙВ ЗРів1°ъ ЗРів2 °ЈҝЎ АҜАЗ№МЗС ВчАМ°Ў АЦҙВ °НАё·О іӘЕёіӘ АЦ°н, ЗРҪАЕВөөөө ЗРів1°ъ
ЗРів2 °ЈҝЎ АҜАЗ№МЗС ВчАМ°Ў АЦҙВ °НАё·О іӘЕёіӘ АЦҪАҙПҙЩ.
ЗРҪАёёБ·өөҙВ ЗРівә°·О АҜАЗ№МЗС ВчАМ°Ў ҫшҙВ °НАё·О іӘЕёіӘ АЦҪАҙПҙЩ.
ЎЎ
өҝАПБэҙЬұә
өҝАПБэҙЬұә әРј®ҝЎјӯҙВ °ў БҫјУәҜјц°ӘҝЎ АЦҫојӯ ҫоҙА өО БэҙЬ°ЈҝЎ АҜАЗАыАО ВчАМ°Ў ҫшАёёй
өҝАПБэҙЬұәАё·О әР·щөЛҙПҙЩ.
-->јцҫчЕВөө
Tukey HSD
ЎЎ
|
|
N |
БэҙЬұә |
|
ЗРів
ЎЎ |
1 |
2 |
|
2 |
6 |
1.67 |
|
|
3 |
6 |
3.00 |
3.00 |
|
1 |
6 |
|
4.33 |
|
АҜАЗИ®·ь |
|
.081 |
.081 |
|
өҝАПБэҙЬұәАЗ ұЧ·мҝЎ ҙлЗС ЖтұХАМ ЗҘҪГөЛҙПҙЩ.
АҜЗь III БҰ°цЗХҝЎ ұвГКЗХҙПҙЩ
ҝАВчЗЧАә ЖтұХБҰ°ц(ҝАВч) = .978АФҙПҙЩ. |
|
a Б¶ИӯЖтұХ ЗҘә» Е©ұв 6.000А»(ёҰ) »зҝлЗХҙПҙЩ. |
|
b АҜАЗјцБШ = .05. |
јцҫчЕВөө ЗҘҝЎјӯ АҜАЗИ®·ьА» әёёй өС ҙЩ АҜАЗ№МЗС °ӘАМ ҫЖҙФА» ҫЛ јц АЦҪАҙПҙЩ. өы¶ујӯ БэҙЬ
1°ъ 2ҙВ өҝАПЗС БэҙЬАУА» ҫЛ јц АЦҪАҙПҙЩ.
ЎЎ
-->ЗРҪАЕВөө
Tukey HSD
ЎЎ
|
|
N |
БэҙЬұә |
|
ЗРів
ЎЎ |
1 |
2 |
|
2 |
6 |
1.83 |
|
|
3 |
6 |
3.00 |
3.00 |
|
1 |
6 |
|
3.33 |
|
АҜАЗИ®·ь |
|
.128 |
.825 |
|
өҝАПБэҙЬұәАЗ ұЧ·мҝЎ ҙлЗС ЖтұХАМ ЗҘҪГөЛҙПҙЩ.
АҜЗь III БҰ°цЗХҝЎ ұвГКЗХҙПҙЩ
ҝАВчЗЧАә ЖтұХБҰ°ц(ҝАВч) = .944АФҙПҙЩ. |
|
a Б¶ИӯЖтұХ ЗҘә» Е©ұв 6.000А»(ёҰ) »зҝлЗХҙПҙЩ. |
|
b АҜАЗјцБШ = .05. |
ЎЎ
ЗРҪАЕВөө ЗҘҝЎјӯ АҜАЗИ®·ьА» әёёй өС ҙЩ АҜАЗ№МЗС °ӘАМ ҫЖҙП№З·О БэҙЬ1°ъ БэҙЬ2ҙВ өҝАПЗС
БэҙЬАУА» ҫЛ јц АЦҪАҙПҙЩ.
ЎЎ
-->ЗРҪАёёБ·
Tukey HSD
ЎЎ
|
|
N |
БэҙЬұә |
|
ЗРів |
1 |
|
2 |
6 |
2.00 |
|
3 |
6 |
2.50 |
|
1 |
6 |
2.67 |
|
АҜАЗИ®·ь |
|
.138 |
|
өҝАПБэҙЬұәАЗ ұЧ·мҝЎ ҙлЗС ЖтұХАМ ЗҘҪГөЛҙПҙЩ.
АҜЗь III БҰ°цЗХҝЎ ұвГКЗХҙПҙЩ
ҝАВчЗЧАә ЖтұХБҰ°ц(ҝАВч) = .322АФҙПҙЩ. |
|
a Б¶ИӯЖтұХ ЗҘә» Е©ұв 6.000А»(ёҰ) »зҝлЗХҙПҙЩ. |
|
b АҜАЗјцБШ = .05. |
-->ЗРҪАёёБ· ЗҘҝЎјӯ АҜАЗИ®·ьА» әёёй ЗРів1ҝН ҙЩёҘ ЗРів°ЈҝЎ АҜАЗ№МЗС °ӘАМ ҫЖҙП№З·О јј БэҙЬАМ
ёрөО өҝАПБэҙЬАУА» ҫЛ јц АЦҪАҙПҙЩ. ұЧ·ҜіӘ јј °ЎБц ЗРҪАИҝ°ъҙВ БҫЗХАыАё·О ЖЗҙЬЗТ ¶§ ёрөО
өҝАПЗПБцҙВ ҫКҙЩ°н ЗТ јц АЦҪАҙПҙЩ.
ЎЎ |
